.jpeg)
Deploy When Available is now GA
Queue for any GPU spec, even one that's fully rented out, and we'll deploy it the moment capacity opens up. No more refreshing the console or running a sniping tool.
All
Blog
Benchmark Qwen2.5-Coder-7B-Instruct across NVIDIA's B200, RTX 5090, and 4090 to identify optimal GPUs for LLM inference, compare token throughput, cost.


Now that the Nvidia Blackwell architecture specs are generally available through the B200 and 5090 GPU models, we’ve benchmarked these powerhouse GPUs using Qwen2.5-Coder-7B-Instruct to help you make informed decisions about your inference infrastructure. The results reveal distinct performance profiles that align with different use cases and budget considerations.
Our benchmark methodology focuses on real-world LLM inference scenarios using Qwen2.5-Coder-7B-Instruct, a production-ready coding model that represents typical enterprise workloads. The test matrix examines performance across four sequence lengths (128, 512, 1024, and 2048 tokens) and three batch sizes (1, 4, and 8 concurrent requests), creating twelve distinct configuration points that mirror common deployment patterns.
To understand these results, it's important to clarify what these key parameters actually mean in practice:
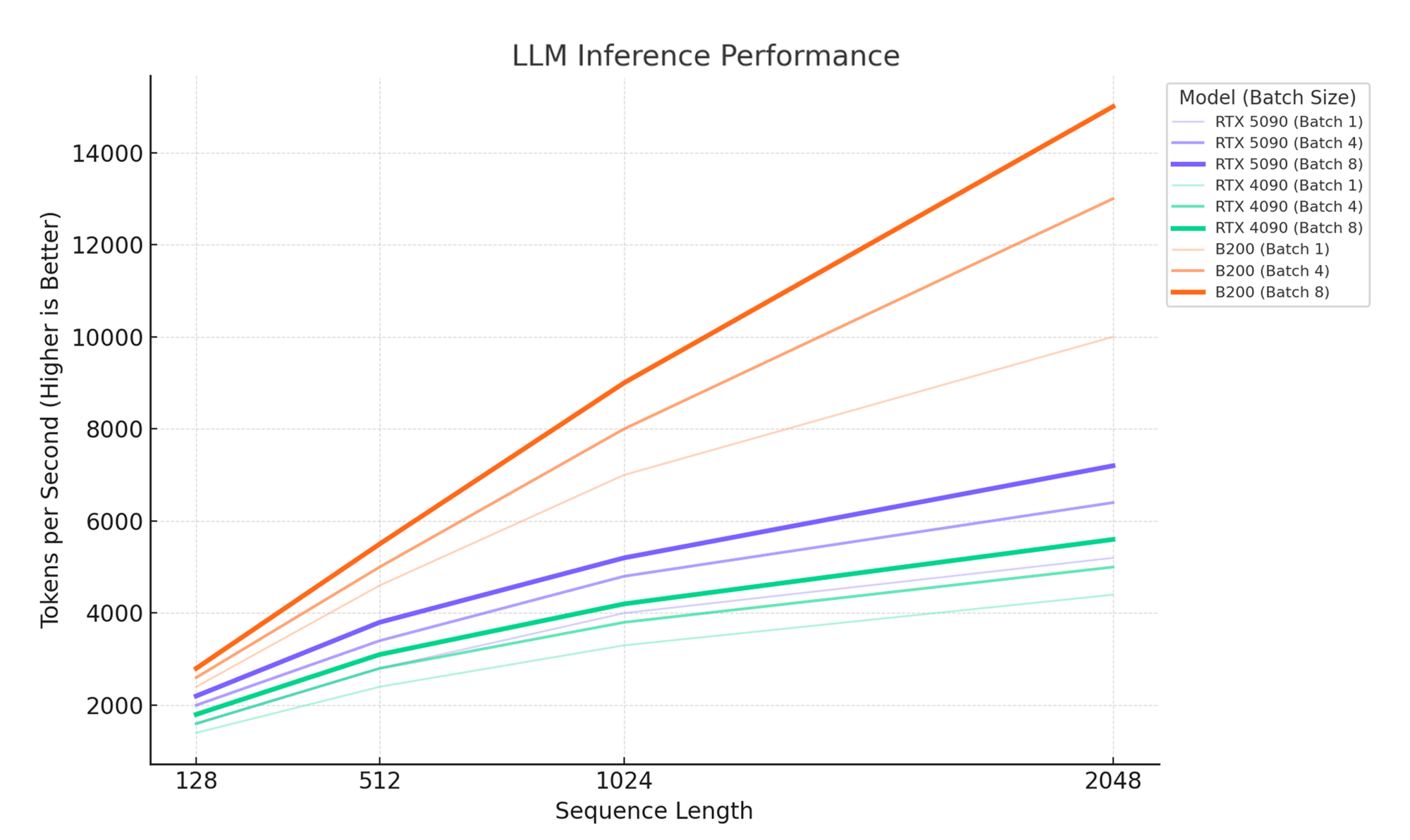
The hardware specifications we're comparing tell an important story about architectural trade-offs. The RTX 5090's 32GB of VRAM and 170 cores represent NVIDIA's latest consumer-focused design, balancing memory capacity with compute density. The RTX 4090's 24GB and 128 cores show the previous generation's constraints, while the B200's massive 183GB memory pool and 148 cores demonstrate enterprise-grade architecture optimized for memory-intensive AI workloads. These differences become particularly pronounced as our benchmark pushes each GPU toward its memory and compute limits.
What makes these benchmarks particularly relevant is how they expose the memory wall that often constrains LLM inference performance. While peak FLOPS matter for training, inference performance depends heavily on memory bandwidth, latency, and capacity. Our token-per-second measurements capture this realzity, showing how each GPU handles the constant shuffle of model weights, attention states, and intermediate calculations that define modern transformer inference.
Let’s add another dimension to the evaluation: cost per tokens/second, as this becomes particularly important if you’re working within our serverless architecture where you are paying per second of GPU time. At writimg, the RTX 4090 is priced at $0.0031 per second and the RTX 5090 at $0.0044 per second. We’ll exclude the B200 here due to this being a more cost-sensitive analysis.
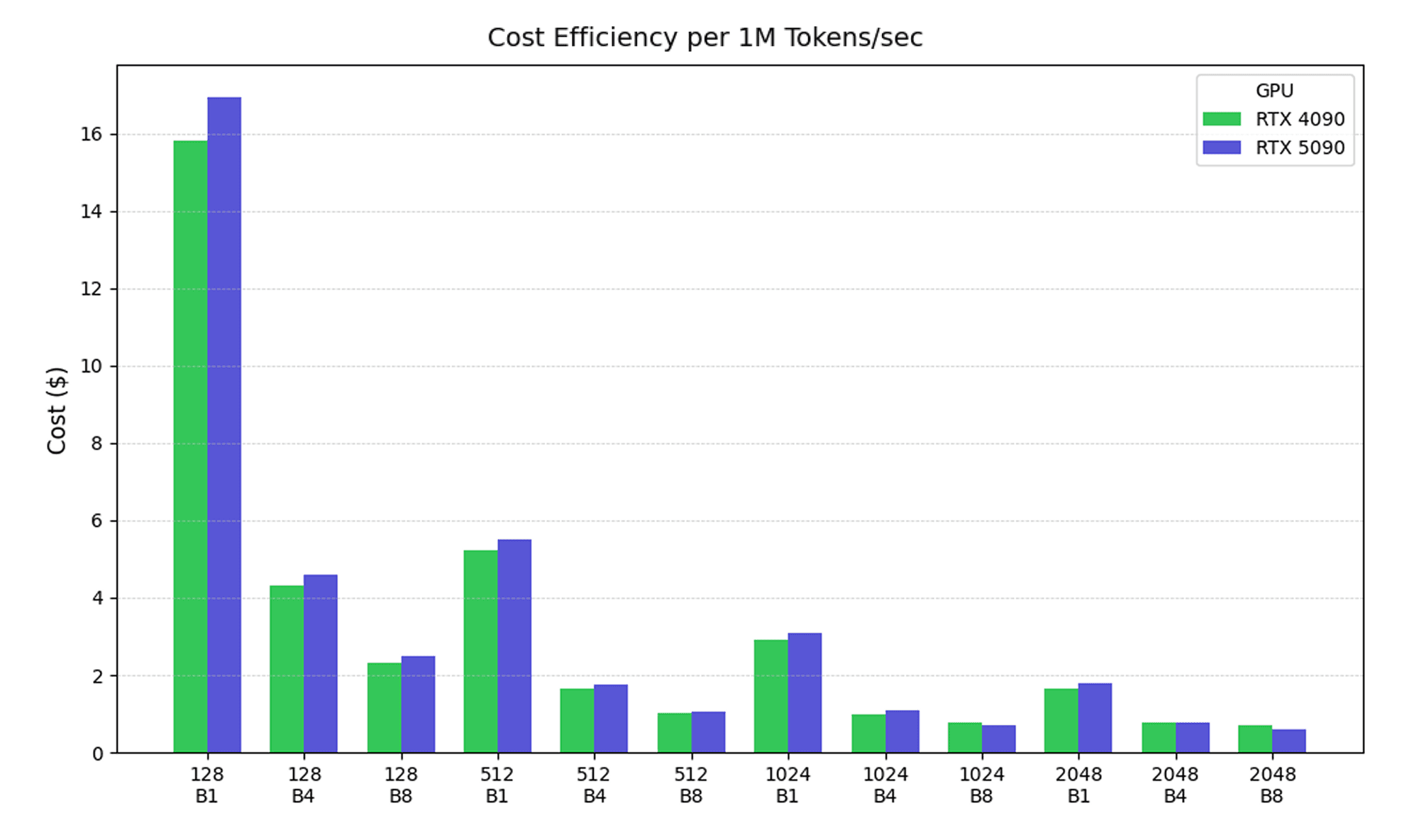
In serverless, the RTX 5090's superior raw performance creates specific cost-efficiency sweet spots in deployments. At 1024-token sequences with 8-batch processing, and 2048-token sequences with 4 or 8-batch processing, the 5090's 20-70% performance advantage finally justifies its 42% cost premium. This demonstrates that for LLMs specifically each model represents a tool in your kit; for larger, more in depth operations, the 5090 is the winner as its superior hardware results in cost savings despite the cost premium.
Understanding raw benchmark numbers is one thing, but translating them into practical deployment scenarios reveals the true value proposition of each GPU option. Let's examine how these performance characteristics play out in common enterprise applications.
Customer Support Chatbots and Interactive Applications
For customer support chatbots handling 50-100 concurrent users with typical response lengths of 128-512 tokens, the RTX 4090 often provides the best cost-performance balance. At 512-token sequences with 4-batch processing, the 4090 delivers 1,847 tokens per second at $0.0031 per second, translating to roughly 596 responses per second per dollar. The RTX 5090's 2,529 tokens per second at this configuration costs significantly more per response, making the performance premium harder to justify for price-sensitive support applications. However, for premium support tiers or complex technical support requiring longer context windows, the 5090's superior memory capacity becomes valuable for handling escalated queries without performance degradation.
Code Generation and Development Workflows
Code generation presents a more complex optimization challenge, as sequence lengths vary dramatically from short function completions (128-512 tokens) to full file generation (1024-2048 tokens). For development platforms processing mixed workloads, the RTX 5090 demonstrates clear advantages in longer-sequence scenarios. At 1024-token sequences with 8-batch processing, the 5090's 5,798 tokens per second significantly outperforms the 4090's 4,077 tokens per second, translating to 42% faster code generation for substantial functions or classes. This performance gap becomes even more pronounced for repository-level analysis or large refactoring tasks, where the 5090's additional memory capacity prevents the memory bottlenecks that can cripple the 4090's performance on complex codebases.
Document Analysis and Content Processing Pipelines
Enterprise document analysis pipelines, particularly those handling legal documents, research papers, or technical specifications, often require processing 2048-token sequences or longer. Here, the architectural differences between consumer and enterprise GPUs become most apparent. While the RTX 5090 reaches 7,198 tokens per second at maximum tested configuration, its performance curve begins flattening due to memory constraints. The B200's 14,045 tokens per second at the same configuration demonstrates why enterprise deployments gravitate toward datacenter hardware. For organizations processing thousands of documents daily, this performance difference translates directly into infrastructure costs and processing time. A document analysis pipeline that takes 8 hours on RTX 5090 hardware might complete in under 4 hours on B200 systems, potentially justifying the higher per-second costs through dramatically reduced total processing time.
The benchmark results reveal that the optimal GPU choice depends heavily on your specific use case and operational requirements. For organizations prioritizing cost efficiency while maintaining solid performance, the RTX 4090 remains competitive, especially for workloads with shorter sequences or lower concurrency requirements. The RTX 5090 emerges as the versatile middle ground, offering substantial performance improvements and increased memory capacity that can handle most production scenarios efficiently.
However, for enterprise applications demanding maximum throughput, especially those involving long sequences or high batch processing, the B200's performance advantages become compelling despite its higher cost. The near-linear scaling we observed with increased batch sizes and sequence lengths suggests that the B200's performance benefits will only become more pronounced as workloads grow more demanding. Organizations planning for future growth or operating at significant scale should seriously consider the B200's long-term value proposition, as its memory capacity and compute resources provide substantial headroom for evolving requirements.
Author profile: Brendan McKeag
Blog Posts
Queue for any GPU spec, even one that's fully rented out, and we'll deploy it the moment capacity opens up. No more refreshing the console or running a sniping tool.

Explore why faster chips have shifted the bottleneck to AI infrastructure, and what that means for teams running production workloads.
.jpeg)
With MIG, we can partition RTX 6000 Pro cards into isolated 24 GB instances. Here's when it makes sense for your workloads.
