.jpeg)
Deploy When Available is now GA
Queue for any GPU spec, even one that's fully rented out, and we'll deploy it the moment capacity opens up. No more refreshing the console or running a sniping tool.
All
Blog
DeepSeek R1 just got a stealthy update, and it's performing better than ever. This post breaks down what changed in the 0528 release, how it impacts.


Earlier this year, DeepSeek dropped a little, experimental reasoning model in the middle of the night that ended up taking the world by storm, shooting to the top of the App Store past closed model rivals and overloading their API with unprecedented levels of demand to the point that they actually had to stop accepting payments while they worked through deployment and technical challenges – all while being open-source, so anyone could pull and load the model on any hardware they wished, even on Runpod. Since then, it has held its own as an open-source option even in the face of closed-source, foundational model upgrades.
Again, earlier this week, true to form, an upgrade was released with little fanfare or preparation. Like its predecessor, DeepSeek-R1-0528 continues to utilize a Mixture-of-Experts (MoE) architecture, now scaled up to an enormous size. This sparse activation allows for powerful specialized expertise in different coding domains while maintaining efficiency. The context also continues to remain at 128k (with RoPE scaling or other improvements capable of extending it further.)
The team refers to it as a "minor upgrade" – and at first blush this does appear to be an incremental update of some kind – but what it is it really?
DeepSeek R1-0528's mathematical reasoning capabilities represent perhaps the most dramatic improvement in the update. In the AIME 2025 test, the model's accuracy has increased from 70% in the previous version to 87.5% in the current version - a remarkable 17.5 percentage point jump that puts it in direct competition with OpenAI's o3 (88.9%) and well ahead of Gemini 2.5 Pro (83.0%).
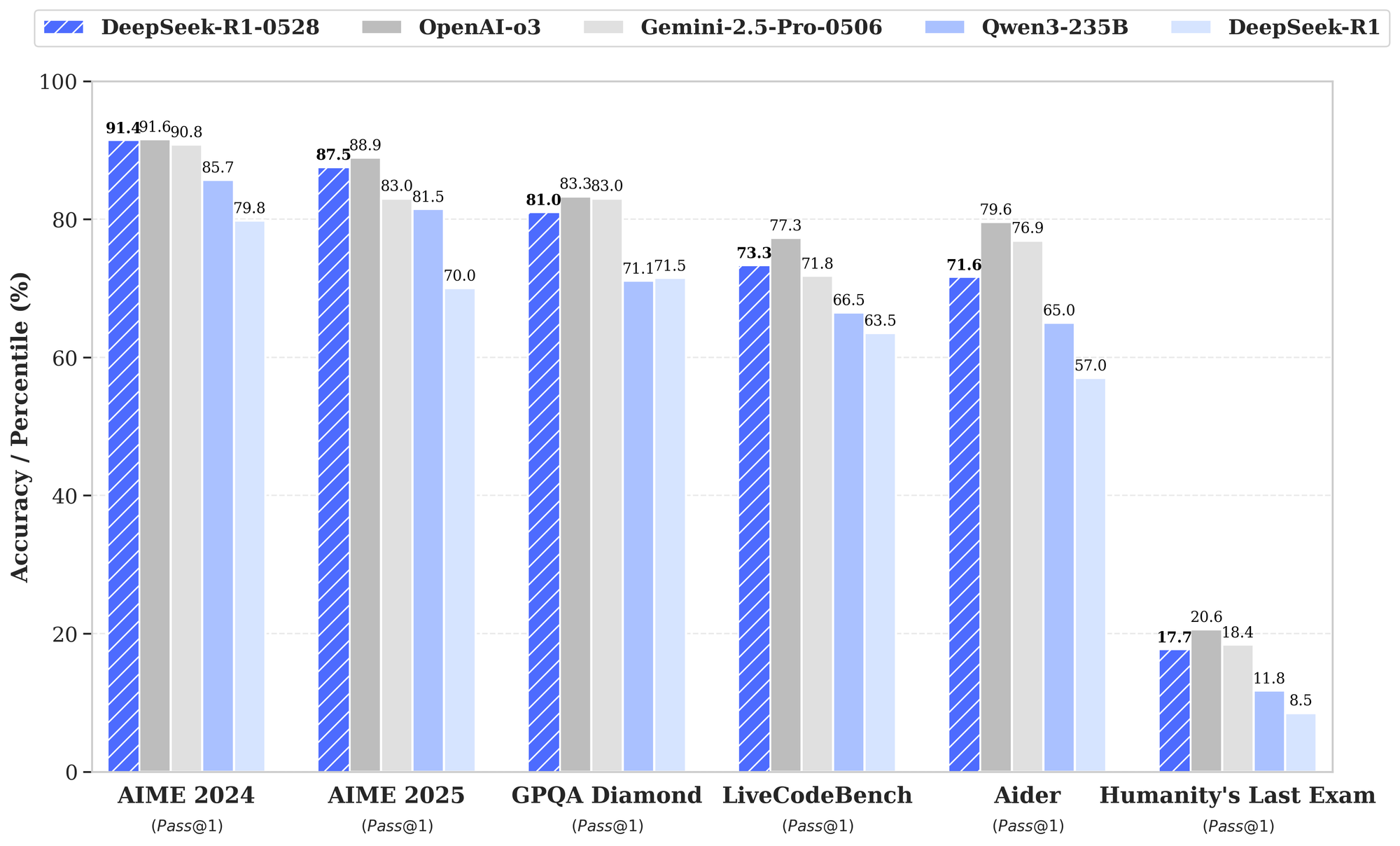
The improvements stem from what DeepSeek calls "enhanced thinking depth." In the AIME test set, the previous model used an average of 12K tokens per question versus 23K tokens in the new version, signaling that the model now engages in much longer, more thorough chains of reasoning. This isn't just about brute force computation - it's about systematic, step-by-step logical analysis.
What sets R1-0528 apart is its ability to handle complex, multi-step mathematical problems that require not just computational ability but genuine mathematical insight. his means the model can check its own work, recognize errors, and course-correct during problem-solving.
Perhaps most impressively, the chain-of-thought from DeepSeek-R1-0528 was distilled to post-train Qwen3 8B Base, obtaining DeepSeek-R1-0528-Qwen3-8B. This model achieves state-of-the-art (SOTA) performance among open-source models on the AIME 2024, surpassing Qwen3 8B by +10.0% and matching the performance of Qwen3-235B-thinking. This suggests that the mathematical reasoning patterns discovered by R1-0528 can be successfully transferred to smaller, more efficient models - something demonstrated previously in the original R1 model and now confirmed through iteration.
On the Live CodeBench challenge platform, DeepSeek-R1-0528 achieved a Pass@1 score of 73.1, placing 4th overall – just shy of OpenAI's "O3 (High)" model at 75.8 and the "O4-Mini (High)" at 80.2. This performance is particularly significant because LiveCodeBench doesn't just test static performance, it challenges a model's dynamic reasoning, its ability to write, iterate, and debug code in realistic software development scenarios.
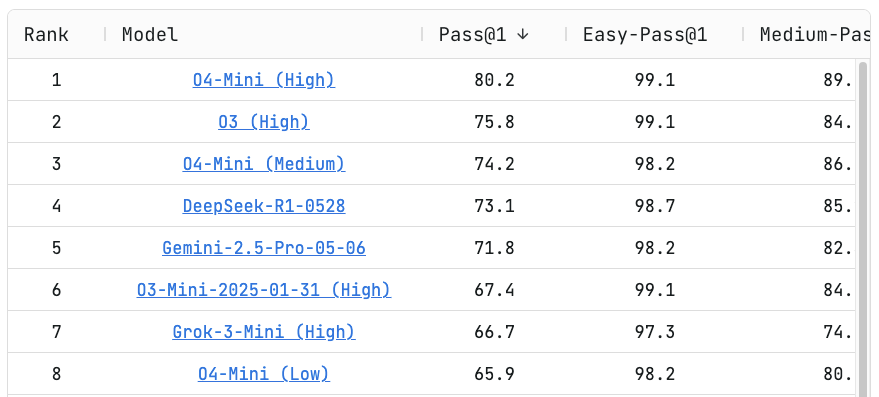
For companies building AI agents that handle PR reviews, Deep Code Review, code refactoring, or real-time developer assistance, the release of DeepSeek-R1-0528 is more than just a benchmark win—it's a practical leap forward. The benchmark is designed to mimic real-world dev scenarios, including PR reviews, iterative debugging, and multi-step reasoning
One of the most significant practical improvements in R1-0528 is the dramatic reduction in AI hallucinations - those troublesome instances where models generate plausible-sounding but factually incorrect information.
DeepSeek said the rate of "hallucinations", false or misleading output, was reduced by about 45-50% in scenarios such as rewriting and summarizing. This isn't just a marginal improvement - it's a fundamental enhancement to the model's reliability and trustworthiness. According to Adina Yakefu, AI researcher at Huggingface, the upgraded model also has "major improvements in inference and hallucination reduction ... this version shows DeepSeek is not just catching up, it's competing." The improvements appear to stem from more consistent factual grounding and lower error rates in multi-step reasoning.
The hallucination reduction appears to be achieved through several mechanisms:
As someone that has experimented with training and studying how LLMs can be used as creative writing partners since the days of Pygmalion-6b, along with extensive experience using the vanilla R1 for the same, here are my thoughts:
KoboldCPP remains the fastest and quickest way to spin up a pod to use quantizations at a fraction of a spend the full weights would cost, since this model is just as weighty as the original R1. Running a model at 8 bit incurs next to no performance tradeoffs while requiring only half of the original hardware, with lower bit quantizations often being just as useful. Check out our previous guide on running this if you'd like to get started, and use the Unsloth GGUF quantizations as a starting point.
Author profile: Brendan McKeag
Blog Posts
Queue for any GPU spec, even one that's fully rented out, and we'll deploy it the moment capacity opens up. No more refreshing the console or running a sniping tool.

Explore why faster chips have shifted the bottleneck to AI infrastructure, and what that means for teams running production workloads.
.jpeg)
With MIG, we can partition RTX 6000 Pro cards into isolated 24 GB instances. Here's when it makes sense for your workloads.
