.jpeg)
Deploy When Available is now GA
Queue for any GPU spec, even one that's fully rented out, and we'll deploy it the moment capacity opens up. No more refreshing the console or running a sniping tool.
All
Blog
Multimodal models handle more than just text, they process images, audio, and more. This guide shows how to deploy and scale them using Runpod’s infrastructure.


Multimodal AI models integrate various types of data, such as text, images, audio, or video, to allow tasks such as image-text retrieval, video question answering, or speech-to-text. Examples are CLIP, BLIP, and Flamingo, among others, showing what is possible by combining these modes–(but deploying them presents unique challenges including high computational requirements, complex data pipelines, and scalability concerns.
Runpod offers a robust cloud platform specifically optimized for AI workloads, making it ideal for deploying resource-intensive multimodal models. This guide provides detailed, step-by-step instructions for successfully deploying multimodal AI models on Runpod.
Multimodal models process complex datasets that combine modalities, such as pairing text and images. This inevitably adds a higher bar to clear for VRAM and compute needs. For example, llama-3.2 90b Vision could be described as the 70b parameters of the LLM itself, with another 20b of vision parameters "bolted on." Most multimodal models require at least 16GB VRAM for inference, bare minimum.
There is always a jam in aligning multiple modalities within the inference pipelines. For example, combining image preprocessing with text embedding generation requires seamless orchestration.
Multimodal deployments demand elasticity to handle varying workloads, especially in production scenarios where demand keeps fluctuating.
Create a Runpod account at runpod.io, if you haven't already done so. Then, select an appropriate GPU instance based on your model requirements. For CLIP/BLIP: a smaller GPU spec like the A40 (48GB) will get the job done. For larger models still, A100 (80GB), H200 (141GB) or multiple GPUs may be necessary.
Runpod offers a number of pre-set templates that comes with most common libraries pre-installed - you can start with the official PyTorch templates, for example.
If you'd rather create and push your own Docker file, that's certainly an option, too. An example Docker build may look something like this:
With your example requirements.txt set up like this:
Here's an example of how you might use CLIP to classify an image, in code:
And here's the code for running queries against an example:
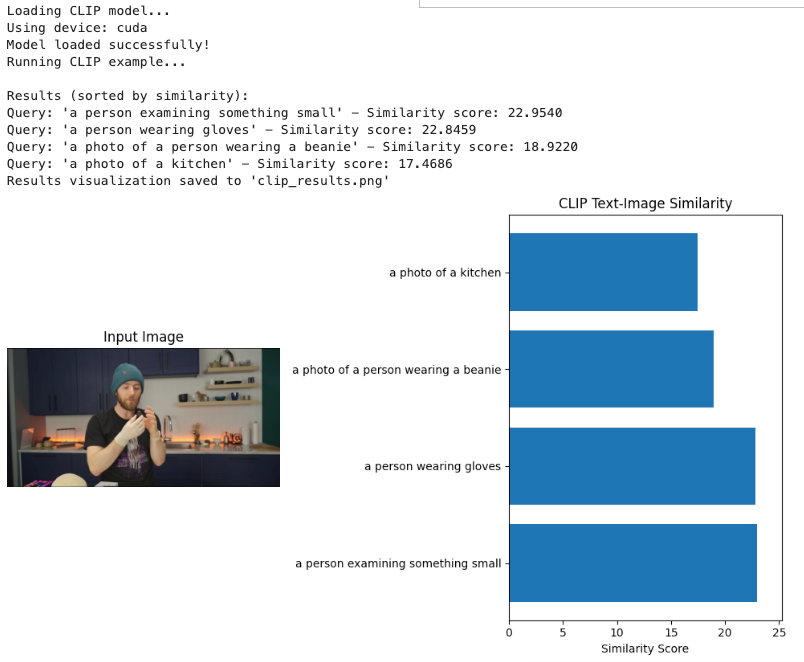
Here's how this would look in action:
Runpod provides an excellent platform for deploying resource-intensive multimodal AI models. By following these detailed steps, you can deploy models like CLIP, BLIP, or Flamingo with optimal performance and scalability. The platform's GPU-focused infrastructure, combined with proper containerization and API design, enables efficient serving of multimodal models for production use cases.
Remember to regularly update your models and monitor performance to ensure your deployment remains efficient and cost-effective over time.
Author profile: James Sandy
Blog Posts
Queue for any GPU spec, even one that's fully rented out, and we'll deploy it the moment capacity opens up. No more refreshing the console or running a sniping tool.

Explore why faster chips have shifted the bottleneck to AI infrastructure, and what that means for teams running production workloads.
.jpeg)
With MIG, we can partition RTX 6000 Pro cards into isolated 24 GB instances. Here's when it makes sense for your workloads.
