.jpeg)
Manage Your Runpod Infrastructure From Any AI Assistant: Introducing the Runpod MCP Server
Your AI assistant can already write your training script. Now it can also spin up the GPU to run it on.
All
Blog
Learn how to quickly create, test, and deploy Runpod Serverless workers using GitHub templates, accelerating AI workloads with pay-per-use efficiency and.


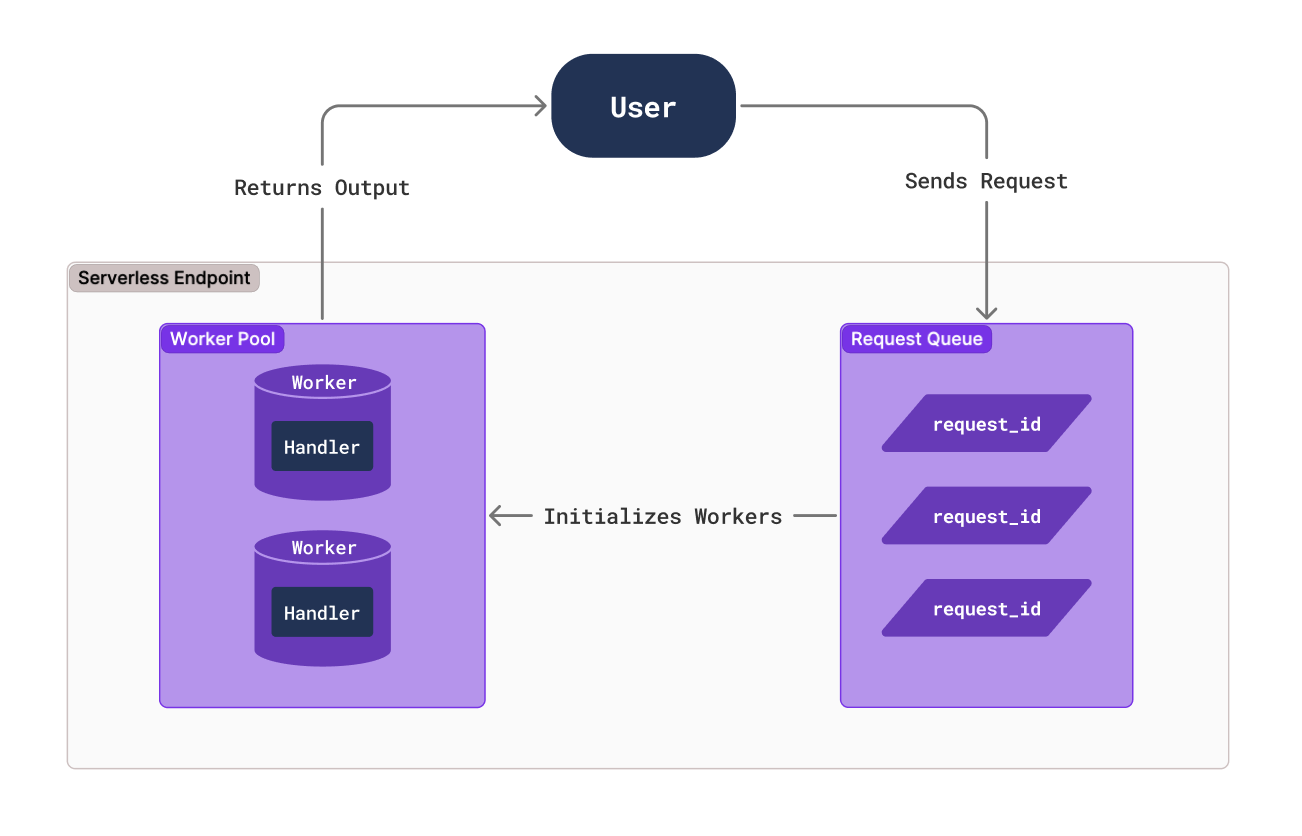
Runpod Serverless is a cloud computing solution designed for short-lived, event-driven tasks. Runpod automatically manages the underlying infrastructure so you don’t have to worry about scaling or maintenance. You only pay for the compute time that you actually use, so you don’t pay when your application is idle.
You configure an endpoint for your Serverless application with compute resources and other settings, and workers process requests that arrive at that endpoint. You create a handler function that defines how workers process incoming requests and return results. Runpod automatically starts and stops workers based on demand to optimize resource usage and minimize cost.
When a client sends a request to your endpoint, it is put into a queue and waits for a worker to become available. A worker processes the request using your handler function and returns a result to the client.
You can certainly create custom workers from scratch, but in most cases it’s easiest to start with a template. Runpod provides several templates to help you get started. Let’s create workers using a few of these templates.
In this blog post you’ll learn how to:
The worker-basic template is a minimal Serverless example. When the endpoint receives a request, Runpod spins up a worker to execute the handler function, which in this case prints out some text and sleeps for a few seconds.
Let’s try testing this template locally:
In this example, the worker simply prints some text and sleeps for a given number of seconds. In a real application, you would replace this with functionality like running a Large Language Model (LLM) or performing some other compute-intensive operation. We will try doing this later.
Let’s look through rp_handler.py so we can understand how it works:
The handler(event) function is the entry point for the worker.
event is a dictionary containing the request input in the input key. Here, we store the input values in local variables, print them to the console, and sleep.
When we run the script, it calls runpod.serverless.start, which requests a worker at the endpoint, and sets the handler function to handler.
We will learn how to deploy a worker later - for now, let’s check out another template.
In this example, the worker simply prints some text. In a real application, you would replace this with functionality like running a Large Language Model (LLM) or performing some other compute-intensive operation. We will try doing this later.
Let’s look through handler.py so we can understand how it works:
As the comments mention, if your handler function uses an LLM, you should load it at the start of your script rather than in the handler function itself so that it’s not loaded every time the handler function is called.
The handler(job) function is the entry point for the worker.
job is a dictionary containing the request input in the input key. Here, we store the input value name in a local variable and print it to the console.
The runpod.serverless.start function requests a worker at the endpoint, and sets the handler function to handler.
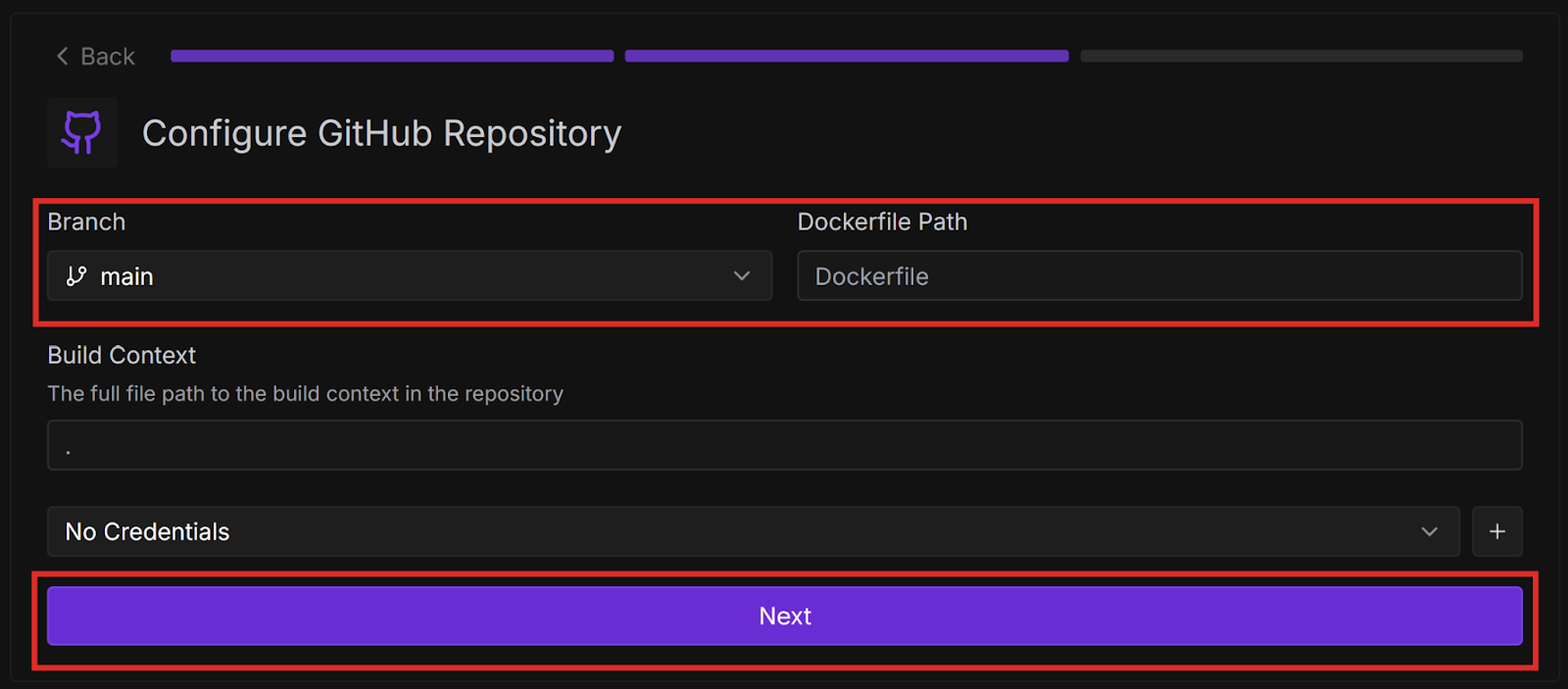
Now that we have learned how to create a simple worker from a template, let’s learn how to deploy it:
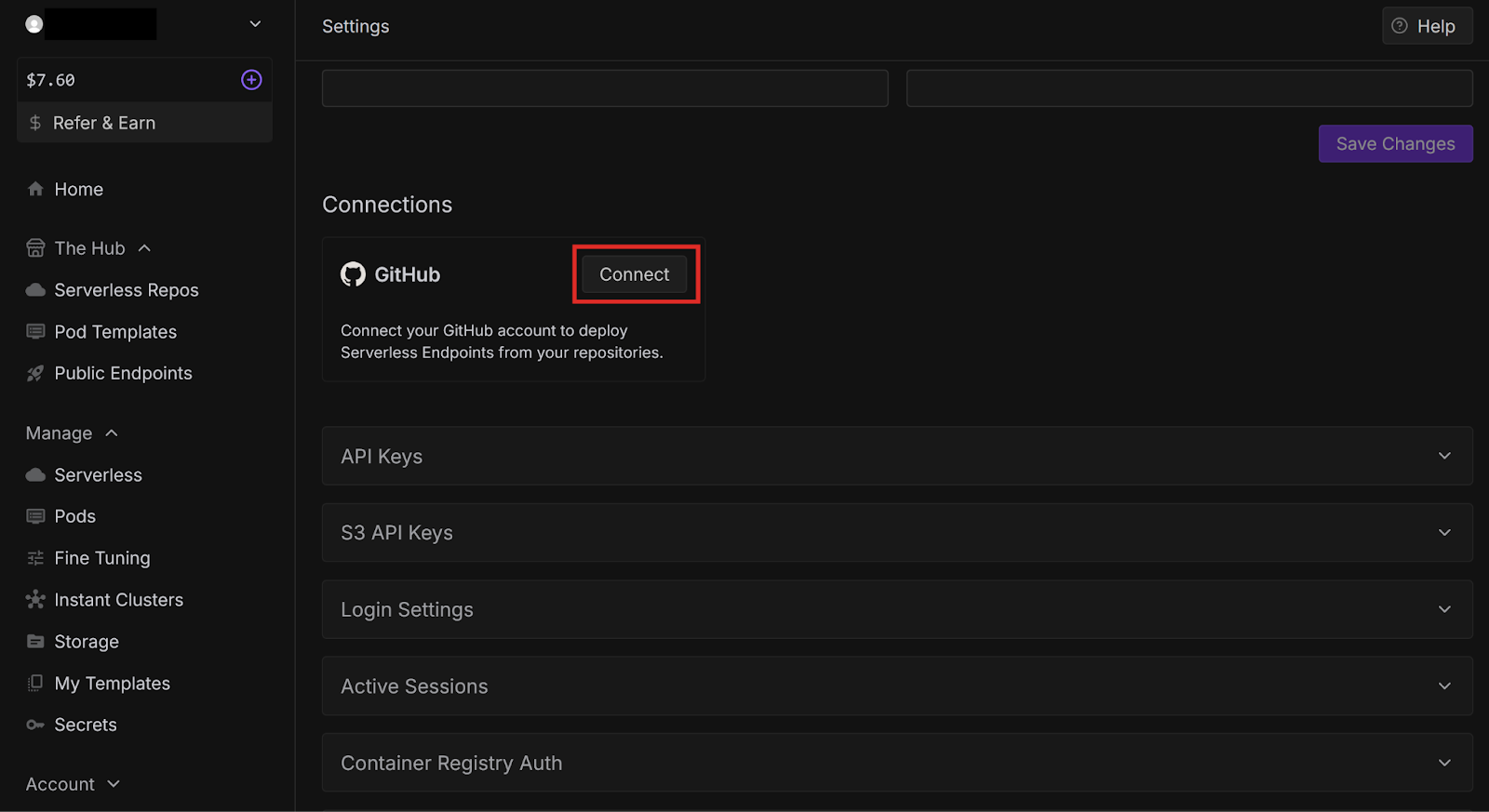

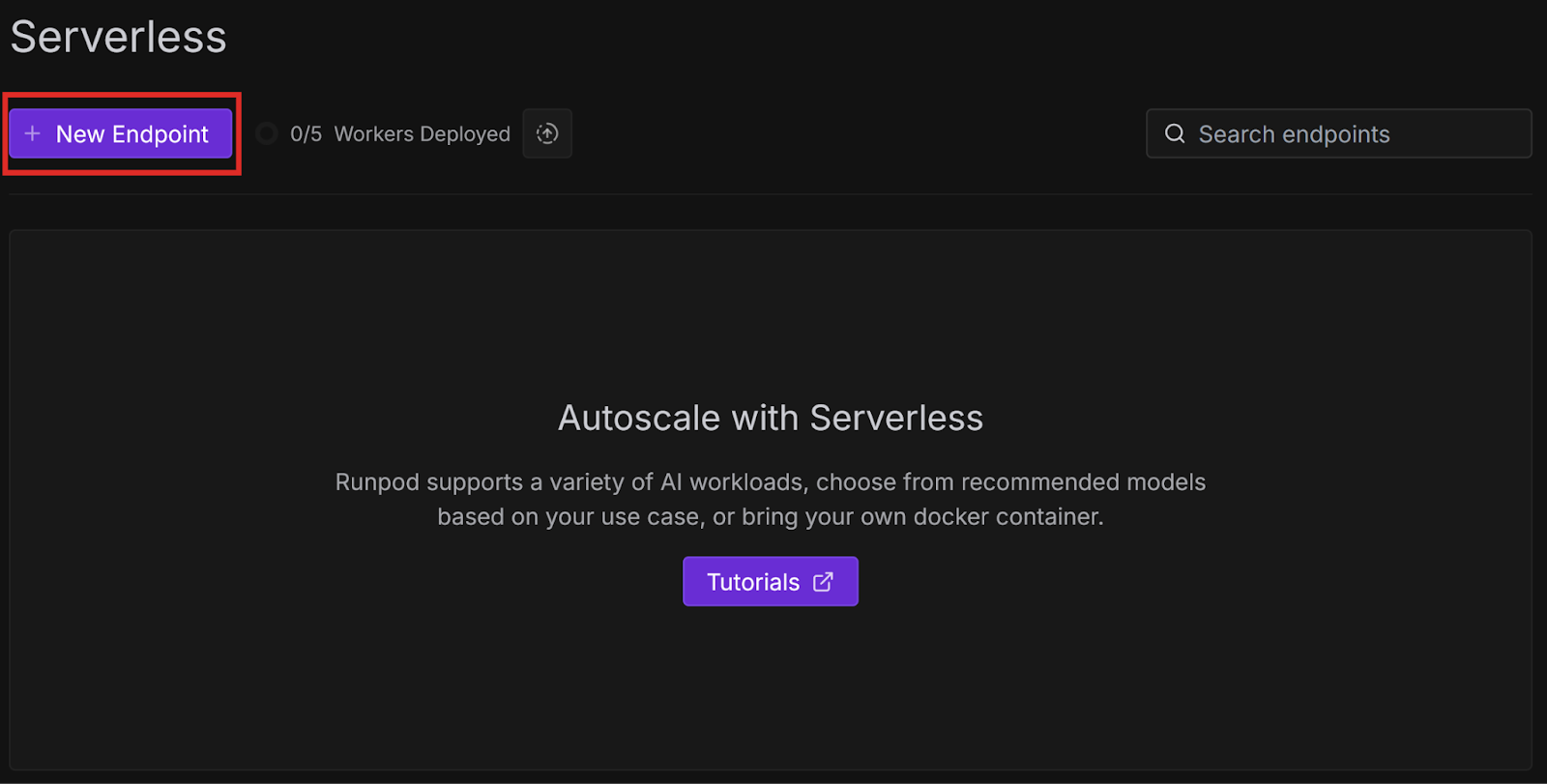

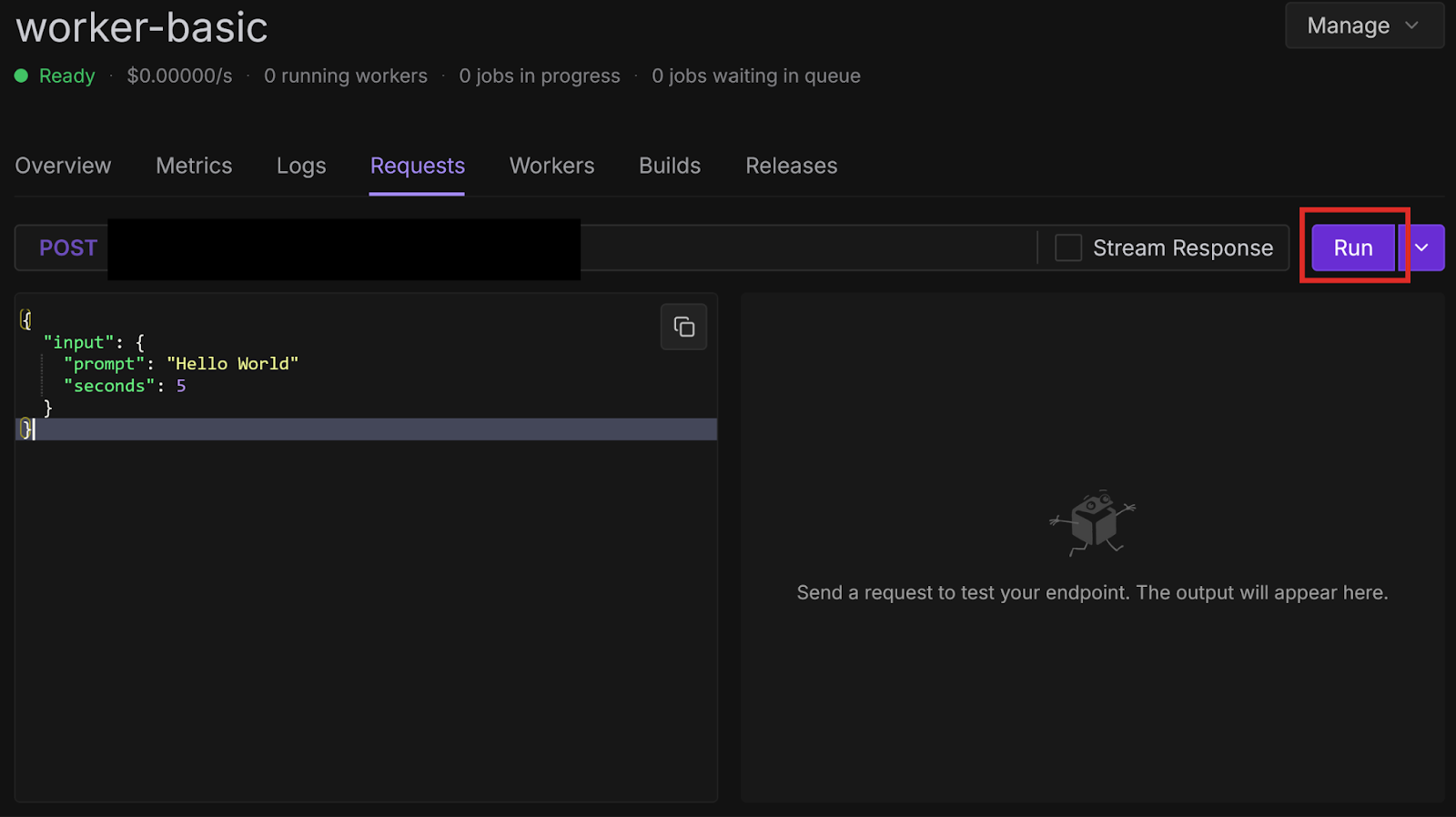
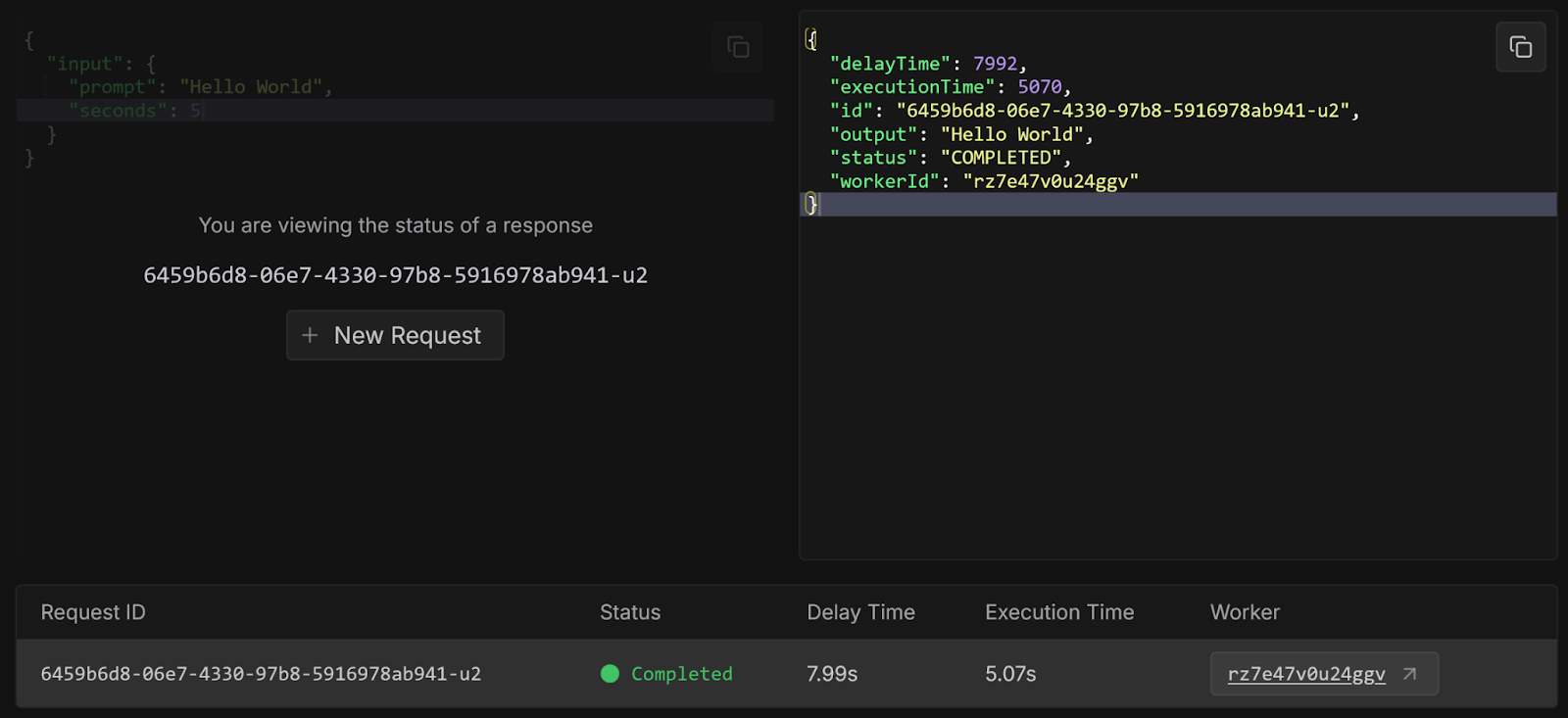
Congratulations, you have successfully created a worker from a template repository and deployed it from GitHub! These examples were very basic, but there are many other more practical templates available, which we will explore in future blog posts. You can also check them out yourself on GitHub.
Try modifying your handler function to do something more interesting, like having an LLM process a query, or running compute-intensive code. You can also implement GitHub Actions for Continuous Integration/Continuous Deployment to automatically test and deploy every time you push to your repository.
Author profile: Eliot Cowley
Blog Posts
Your AI assistant can already write your training script. Now it can also spin up the GPU to run it on.

Learn how Runpod replaced database polling with a CDC-powered event streaming architecture that keeps databases, services, and Snowflake in sync without manual coordination.

Flash deploys Python functions as serverless GPU endpoints in under 30 seconds. FlashBoot cuts serverless GPU inference cold starts to under 200ms. Here's how both work.
