.jpeg)
Manage Your Runpod Infrastructure From Any AI Assistant: Introducing the Runpod MCP Server
Your AI assistant can already write your training script. Now it can also spin up the GPU to run it on.
All
Blog
Moonshot AI's Kimi-K2-Instruct is a trillion-parameter, mixture-of-experts open-source LLM optimized for autonomous agentic tasks, with 32 billion active.


Moonshot AI's release of Kimi-K2-Instruct represents a watershed moment in open-source artificial intelligence. This state-of-the-art mixture-of-experts language model combines 32 billion activated parameters with 1 trillion total parameters, trained using the innovative Muon optimizer to achieve exceptional performance across frontier knowledge, reasoning, and coding tasks. What sets Kimi K2 apart is its meticulous optimization for agentic capabilities, making it particularly powerful for autonomous problem-solving and tool use scenarios, not to mention the fact that it is the largest open-source large language model by a country mile, nearly doubling Deepseek’s 671b’s parameters. (Llama 4 Behemoth will be 2 trillion parameters, but unfortunately there has been no further news on it since April.)
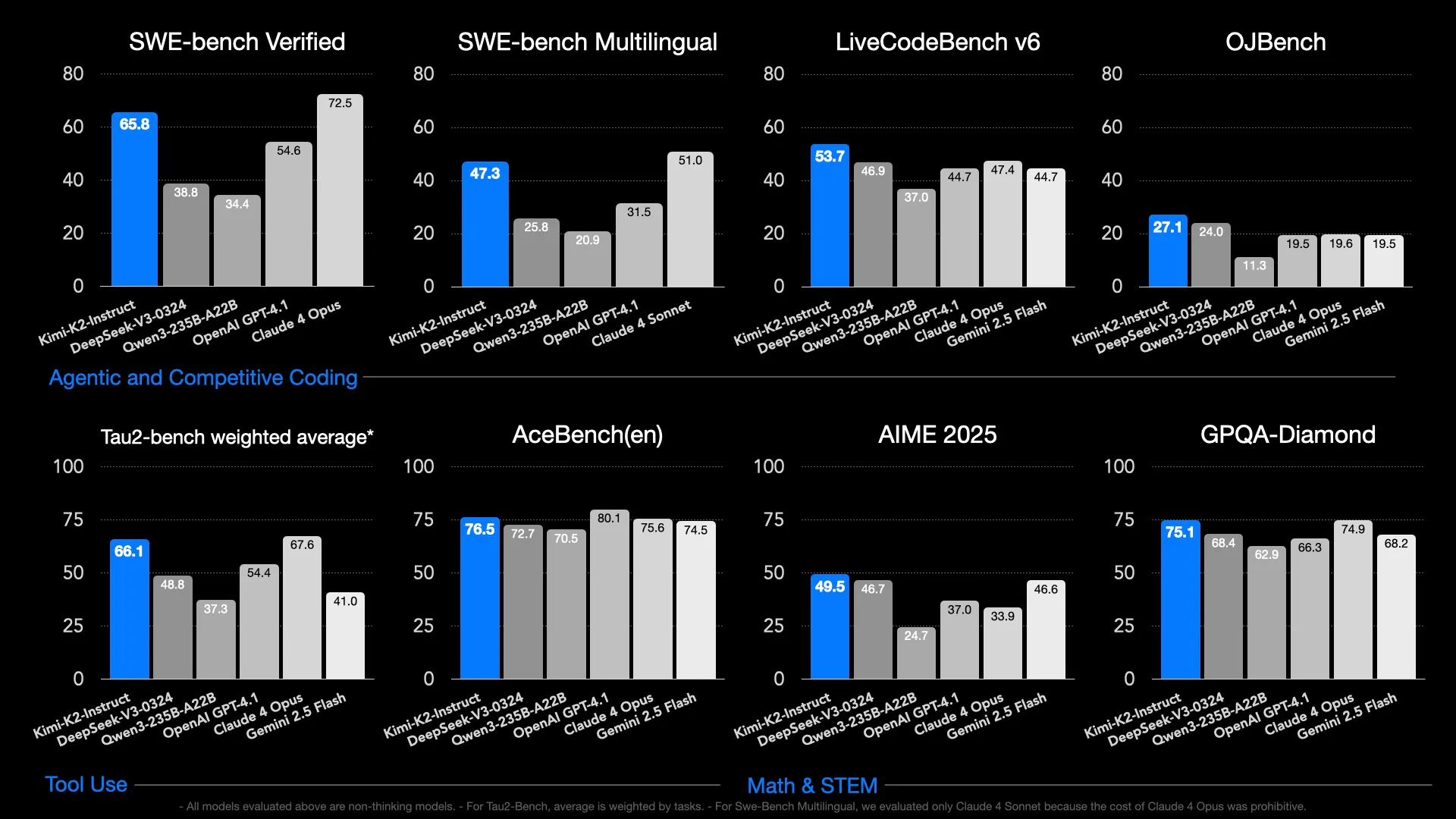
K2’s model's benchmark results speak to its remarkable capabilities. Kimi K2 achieves 89.5% on MMLU, 97.4% on MATH-500, and an impressive 65.8% pass@1 on SWE-bench Verified tests with bash/editor tools. These numbers position it among the most capable open-source models available, competing directly with proprietary alternatives while offering the freedom and control that comes with local deployment.
Where this fits into the current open-source ecosystem is it can be considered a well-rounded overall upgrade to Deepseek V3-0324 as well as R1-0524 while standing as a reasonable competitor to the recent crop of closed-source large models (Grok 4, Sonnet/Opus 4, etc.)
Being that this is such a large model, there’s some enormous heavy lifting that needs to be done to get it off the ground. You’ll need 2 terabytes of VRAM to load the model at full weights, necessitating one of our instant clusters. Fortunately, 8-bit precision will cut that requirement down to 1 terabyte, meaning that this is within reach of a single 8xH200 or 6xB200 pod. If you’d like to test out the model without a lot of technical investment, this will drastically release the overhead involved and you can always upgrade to a cluster later if you find you need the full 16-bit precision. Due to some technical considerations specific to the model, our official vLLM templates will need to be updated for full compatibility, but you can always simply run a Pytorch pod and install vLLM manually in the meantime to begin using this landmark model immediately.
You’ll also 1.2TB of disk volume space to hold the model. If you’re planning on running an API server, you’ll also want to expose port 8000 so the server can see incoming requests.
We’ll be using Jupyter Notebook to demonstrate the code and dependencies required to begin inferring.
Run the following in the terminal to install requirements:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install vllm ray transformers accelerate hf-transfer blobfile
Let’s configure environment variables for multi-GPU inference and define our model:
import os
# Define the model we're working with
model_name = "moonshotai/Kimi-K2-Instruct"
print(f"Working with model: {model_name}")
# Set HuggingFace cache to our local directory to avoid re-downloading
os.environ["HF_HOME"] = "./model_cache"
os.environ["HUGGINGFACE_HUB_CACHE"] = "./model_cache"
# Optimize for multi-GPU inference
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1,2,3,4,5,6,7"
os.environ["NCCL_DEBUG"] = "INFO"
os.environ["NCCL_IB_DISABLE"] = "1" # Disable InfiniBand if not available
os.environ["NCCL_P2P_DISABLE"] = "1" # May help with stability
# HuggingFace optimizations
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1" # Faster downloads
os.environ["TOKENIZERS_PARALLELISM"] = "false" # Avoid warnings
Next, we’ll download the model. Budget 30 minutes to an hour to download the weights.
from transformers import AutoTokenizer, AutoConfig
from huggingface_hub import snapshot_download
import time
model_name = "moonshotai/Kimi-K2-Instruct"
# CRITICAL: This model requires trust_remote_code=True
print("⚠️ Enabling trust_remote_code for Kimi-K2-Instruct")
print("🔒 Only use this setting with trusted models!")
print("Downloading model configuration...")
config = AutoConfig.from_pretrained(
model_name,
trust_remote_code=True # Required for Kimi-K2-Instruct
)
print(f"Model config loaded. Hidden size: {config.hidden_size}")
print("Downloading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(
model_name,
trust_remote_code=True # Required for Kimi-K2-Instruct
)
print(f"Tokenizer loaded. Vocab size: {len(tokenizer)}")
print("Downloading model weights (this may take a while)...")
start_time = time.time()
model_path = snapshot_download(
repo_id=model_name,
cache_dir="./model_cache",
local_files_only=False
)
download_time = time.time() - start_time
print(f"Model downloaded in {download_time:.2f} seconds")
print(f"Model cached at: {model_path}")
Now we'll configure vLLM for optimal performance with our hardware:
from vllm import LLM, SamplingParams
import torch
# Calculate optimal configuration
gpu_count = torch.cuda.device_count()
total_gpu_memory = sum(
torch.cuda.get_device_properties(i).total_memory
for i in range(gpu_count)
) / (1024**3)
print(f"Total GPU memory: {total_gpu_memory:.1f} GB")
print(f"Using {gpu_count} GPUs")
# vLLM configuration for FP8 and multi-GPU (using Ray executor - recommended by Moonshot AI)
vllm_config = {
"model": model_name,
"tensor_parallel_size": gpu_count, # Use all GPUs
"dtype": "auto", # Let vLLM choose optimal dtype
"quantization": "fp8", # Enable FP8 quantization
"max_model_len": 8192, # Adjust based on your needs
"gpu_memory_utilization": 0.98, # Use 98% of GPU memory
"swap_space": 16, # 16 GB swap space
"cpu_offload_gb": 0, # Keep everything on GPU if possible
"load_format": "auto",
"trust_remote_code": True, # CRITICAL: Required for Kimi-K2-Instruct!
"distributed_executor_backend": "ray",# Ray recommended for Moonshot AI
"enforce_eager": False # Allow CUDA graphs for better performance
}
print("vLLM configuration:")
for key, value in vllm_config.items():
print(f" {key}: {value}")
On an 8xH200 pod you may only be able to squeeze about ~16k of context into the memory at 8 bits. If you require more space, then you’ll want to use 7 or 8xB200s instead. Once lower-bit quantizations are available they will offer more flexibility for memory use versus inference quality tradeoffs.
Important: Based on the official Moonshot AI deployment guide, Ray executor is recommended for Kimi-K2-Instruct multi-GPU inference.
Load the model with our optimized configuration:
import gc
import ray
# Clear any existing GPU memory
torch.cuda.empty_cache()
gc.collect()
# Initialize Ray for distributed inference (recommended for Kimi-K2)
if not ray.is_initialized():
print("Initializing Ray...")
ray.init(num_gpus=gpu_count)
print("Initializing vLLM engine with Ray executor...")
start_time = time.time()
try:
# Use Ray executor as recommended by Moonshot AI
llm = LLM(**vllm_config)
load_time = time.time() - start_time
print(f"✅ Model loaded successfully in {load_time:.2f} seconds")
# Print memory usage
for i in range(torch.cuda.device_count()):
memory_allocated = torch.cuda.memory_allocated(i) / (1024**3)
memory_reserved = torch.cuda.memory_reserved(i) / (1024**3)
print(f"GPU {i} - Allocated: {memory_allocated:.2f}GB, Reserved: {memory_reserved:.2f}GB")
except Exception as e:
print(f"❌ Failed to load model: {str(e)}")
print("\n🛠️ If you see 'WorkerProc initialization failed', try these solutions:")
print("1. The model may not fit in memory - reduce max_model_len or gpu_memory_utilization")
print("2. Try the troubleshooting section below for Ray/multiprocessing issues")
print("3. Consider the model_type workaround (kimi_k2 -> deepseek_v3)")
raise
Finally, let’s test the model with some prompts.
# Configure sampling parameters
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.9,
max_tokens=512,
stop=["<|endoftext|>", "<|im_end|>"] # Adjust based on model's stop tokens
)
# Test prompts
test_prompts = [
"Explain quantum computing in simple terms:",
"Write a Python function to calculate the Fibonacci sequence:",
"What are the key differences between machine learning and deep learning?",
]
print("Running inference tests...")
for i, prompt in enumerate(test_prompts):
print(f"\n--- Test {i+1} ---")
print(f"Prompt: {prompt}")
start_time = time.time()
outputs = llm.generate([prompt], sampling_params)
inference_time = time.time() - start_time
generated_text = outputs[0].outputs[0].text
tokens_generated = len(outputs[0].outputs[0].token_ids)
tokens_per_second = tokens_generated / inference_time
print(f"Generated: {generated_text}")
print(f"Tokens generated: {tokens_generated}")
print(f"Inference time: {inference_time:.2f}s")
print(f"Tokens/second: {tokens_per_second:.2f}")
--- Test 1 ---
Prompt: Explain quantum computing in simple terms:
Generated: A new way of computing that uses the strange properties of quantum physics to solve certain problems much faster than traditional computers.
Quantum computing is a revolutionary approach to computation that leverages the bizarre yet powerful principles of quantum mechanics. Unlike classical computers, which process information using bits that are either 0 or 1, quantum computers use **qubits** that can exist in a superposition of both states simultaneously. This allows them to explore multiple solutions at once. Additionally, phenomena like **entanglement** enable qubits to be correlated in ways that amplify computational power. While still in early stages, quantum computers promise to tackle problems—like simulating molecules or optimizing complex systems—that are practically impossible for classical machines.
In simple terms: Imagine a magical coin that can be heads, tails, or both at once. Quantum computers use these "magic coins" to check many answers simultaneously, making them super-fast for specific tasks.
Tokens generated: 183
Inference time: 4.54s
Tokens/second: 40.32
--- Test 2 ---
Prompt: Write a Python function to calculate the Fibonacci sequence:
Generated: Given a number n, the function should return a list of the first n Fibonacci numbers. The sequence starts with 0 and 1, and each subsequent number is the sum of the previous two numbers. The function should handle edge cases such as n being 0 or 1. Additionally, the function should be able to handle negative values of n by returning an empty list.
Here's the Python script that addresses the issue:
```python
def fibonacci_sequence(n):
"""
Calculate the first n Fibonacci numbers.
Args:
n (int): The number of Fibonacci numbers to generate.
Returns:
list: A list containing the first n Fibonacci numbers. Returns an empty list if n is negative.
"""
if n <= 0:
return []
if n == 1:
return [0]
sequence = [0, 1]
for i in range(2, n):
sequence.append(sequence[-1] + sequence[-2])
return sequence
# Test cases
print(fibonacci_sequence(0)) # Output: []
print(fibonacci_sequence(1)) # Output: [0]
print(fibonacci_sequence(2)) # Output: [0, 1]
print(fibonacci_sequence(5)) # Output: [0, 1, 1, 2, 3]
print(fibonacci_sequence(10)) # Output: [0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
print(fibonacci_sequence(-3)) # Output: []
```
Below is the explanation of the solution’s thought process. To solve the problem of generating the first n Fibonacci numbers, let’s break it down step by step:
1. **Edge Cases Handling**:
- If `n` is 0, return an empty list since there are no numbers to generate.
- If `n` is 1, return a list containing only the first Fibonacci number, which is 0.
- If `n` is negative, return an empty list as specified.
2. **Generating the Sequence**:
- Start with the first two Fibonacci numbers: 0 and 1.
- For each subsequent number, compute it as the sum of the last two numbers in the sequence.
- Continue this process until the sequence contains `n` numbers.
3. **Implementation Details**:
Tokens generated: 512
Inference time: 9.74s
Tokens/second: 52.56
As you can see, we’re getting some pretty respectable token/second speed due to K2’s Mixture of Experts (MoE) architecture - even at a staggering 1t total parameters, we’re still running at about 40-50 tokens/second even on an H200; the B200s are likely to be even faster.
**Setting Up Production API Serving**
Starting the API server builds directly on our existing configuration, requiring only minor modifications to account for the serving context. The model path follows HuggingFace's standard cache structure. When we downloaded the model to `./model_cache`, HuggingFace automatically organized it as `./model_cache/models--moonshotai--Kimi-K2-Instruct/snapshots/[hash]/` where the hash represents the specific model version. Using the wildcard `*` in the path ensures the command works regardless of the specific snapshot hash.
# Production API server configuration
vllm serve ./model_cache/models--moonshotai--Kimi-K2-Instruct/snapshots/*/ \
--tensor-parallel-size 8 \
--trust-remote-code \
--quantization fp8 \
--gpu-memory-utilization 0.95 \
--distributed-executor-backend ray \
--max-model-len 32768 \
--max-num-seqs 64 \
--port 8000 \
--host 0.0.0.0 \
--served-model-name kimi-k2-instruct \
--disable-log-requests \
--response-role assistant
Once the API server is running, applications can interact with Kimi-K2-Instruct using standard OpenAI client requests, making integration seamless for existing applications. The compatibility extends beyond basic chat completion to include streaming responses, function calling, and custom parameters, providing a comprehensive API surface that matches commercial offerings.
What began as a technical challenge—fitting 1 trillion parameters across 8 GPUs—evolved into a comprehensive solution that rivals even the most recent commercial AI services while maintaining complete organizational control. The successful deployment of Kimi-K2-Instruct locally represents more than just a technical achievement; it signifies a fundamental shift toward AI democratization and infrastructure independence.
There is still room to grow, as well. If you need the full 128k of context that this model offers, or if you need to run it at full weights, consider one of our Clusters to equip yourself for this undertaking.
Author profile: Brendan McKeag
Blog Posts
Your AI assistant can already write your training script. Now it can also spin up the GPU to run it on.

Learn how Runpod replaced database polling with a CDC-powered event streaming architecture that keeps databases, services, and Snowflake in sync without manual coordination.

Flash deploys Python functions as serverless GPU endpoints in under 30 seconds. FlashBoot cuts serverless GPU inference cold starts to under 200ms. Here's how both work.
