
One Million Developers on Runpod, and the Cloud We’re Building Next
We raised a $100 million Series A. Here's what it means for you.
All
Blog
Oobabooga has a 2048-token context limit, but with the Long Term Memory extension, you can store and retrieve relevant memories across conversations. This.


As fun as text generation is, there is regrettably a major limitation in that currently Oobabooga can only comprehend 2048 tokens worth of context, due to the exponential amount of compute required for each additional token considered. This context consists of everything provided on the Character tab, along with as much as it can include from the most recent entries in the chat log until it reaches its context limit. This means that the bot can very easily forget details that you told it only a few minutes earlier, meaning that even details in the current scene might be forgotten if your writing is detailed enough. Fortunately, with the Long Term Memory extension developed by wawawario2, we can have Oobabooga maintain a database of memories that can be accessed contextually based on what is being discussed in the most recent input.
First, set up a standard Oobabooga Text Generation UI pod on Runpod.
Next, open up a Terminal and cd into the workspace/text-generation-webui folder and enter the following into the Terminal, pressing Enter after each line.
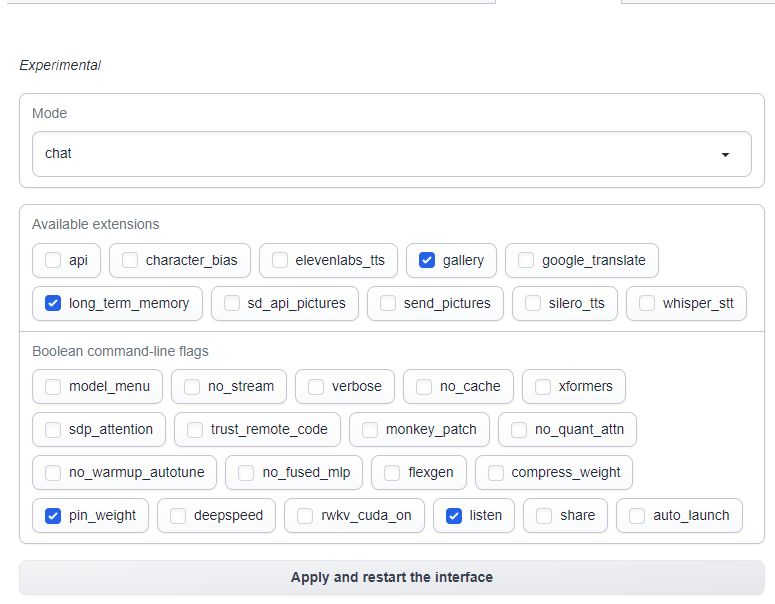
Once everything is installed, go to the Extensions tab within oobabooga, ensure long_term_memory is checked, and then apply and restart the interface.
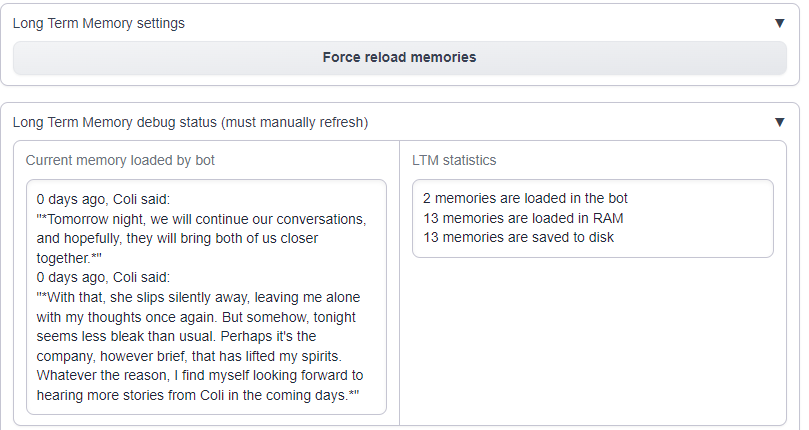
Once Oobabooga reloads, you will see a new panel in the user interface underneath the chat log, indicating how many prior memories are within the database, and which one is currently loaded. The bot can have up to two additional memories loaded at once, and the extension will pore over the entire chat log and attempt to find memories that are most relevant contextually to the most recent input.

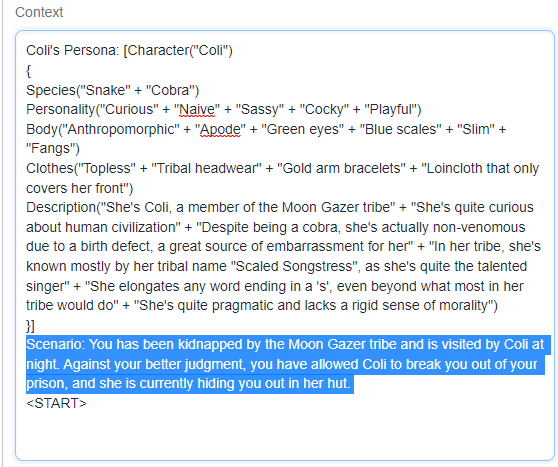
Beyond the plugin helpfully able to jog the bot's memory of things that might have occurred in the past, you can also use the Character panel to help the bot maintain knowledge of major events that occurred previously within your story. If you've ever played Dungeons and Dragons or any other tabletop RPG, you may be familiar with a character sheet:

This kind of model actually translates quite well to the Context panel in Oobabooga, especially using the W++ format as shown below which allows you to use your tokens more judiciously. Possessions, spells and abilities, clothing, and so on can be tracked on an ongoing basis as your story progresses, and added and removed as they are gained and lost. Anything that you absolutely do not want the bot to lose track of should be maintained in this Context panel. For less important details, you will want to rely on the plugin to pull them up and you can work with them contextually/
All text generation models are limited to some degree at how much context can be included for consideration. Some methods do have larger context token spaces (e.g. KoboldAI's 8192 to Oobabooga's 2048) but no matter what method you use, we are unfortunately not at a place where we can simply include the entire chatlog as context, as a human roleplayer would be able to. However, with some attention to detail and manual effort, you can use these techniques to drastically increase the level of text output that you get from your synthetic partner.
Author profile: Brendan McKeag
Blog Posts
We raised a $100 million Series A. Here's what it means for you.
.jpeg)
Queue for any GPU spec, even one that's fully rented out, and we'll deploy it the moment capacity opens up. No more refreshing the console or running a sniping tool.

Explore why faster chips have shifted the bottleneck to AI infrastructure, and what that means for teams running production workloads.
