Alibaba's Qwen3 is here, with major performance improvements and a full range of models from 0.5B to 72B parameters. This post breaks down what's new, how.
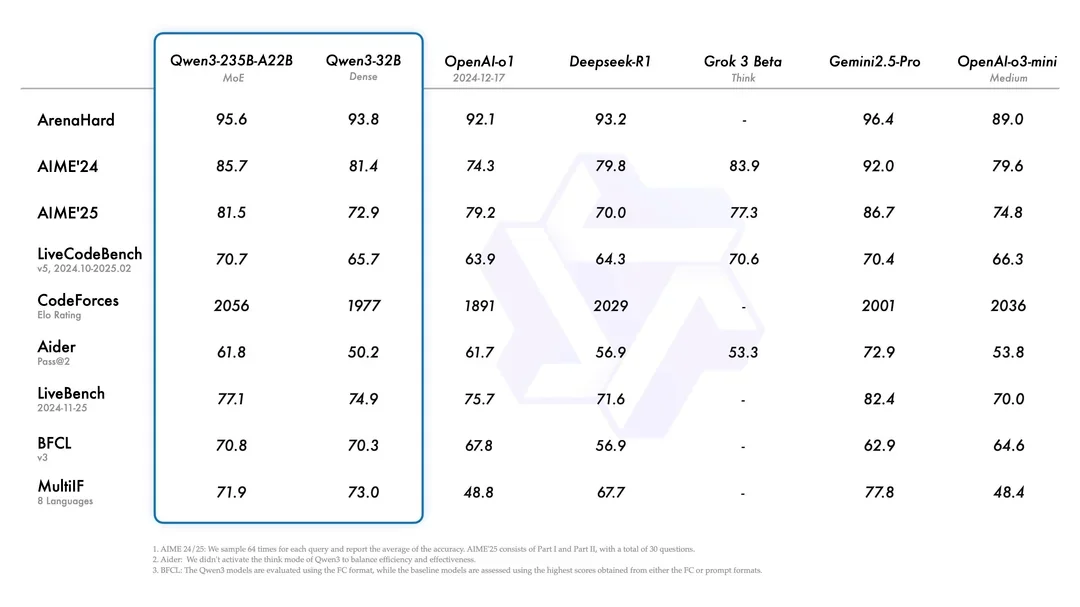
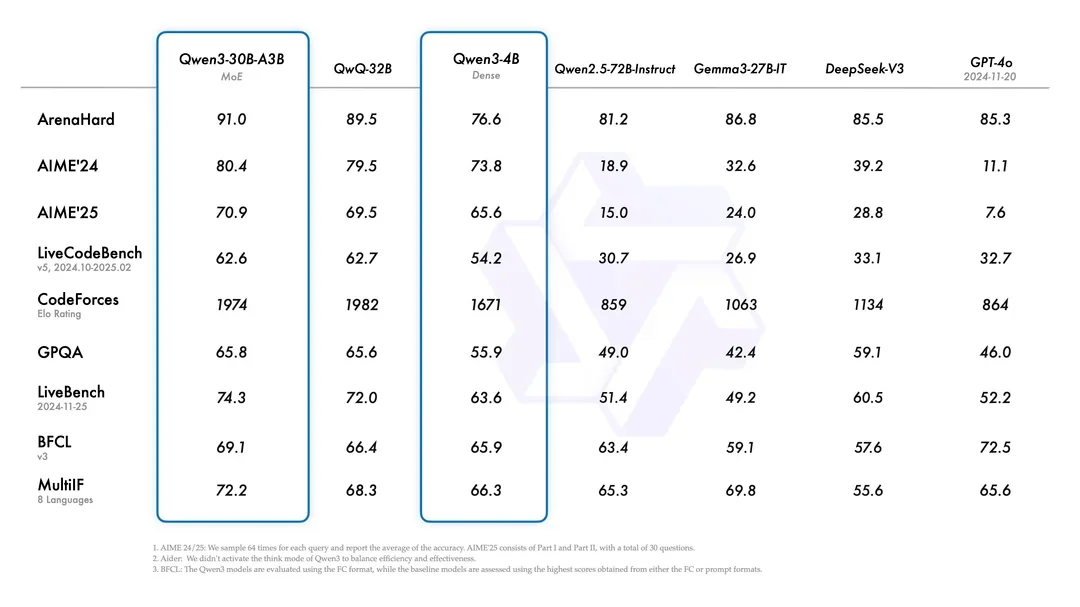
The Qwen Team has released Qwen3, their latest generation of large language models that brings groundbreaking advancements to the open-source AI community. This comprehensive suite of models ranges from lightweight 0.6B parameter versions to massive 235B parameter Mixture-of-Experts (MoE) architectures, all designed with a unique "thinking mode" capability. According to their benchmarks, these models are showing competitive performance against top-tier proprietary models including OpenAI's o1, Google's Gemini, and DeepSeek's R1 in areas like instruction following, coding, mathematics, and complex problem-solving .
The Qwen3 Model Family and Popular Use Cases
Qwen3 is available in a range of sizes to accommodate different deployment scenarios. All models support context lengths of up to 32,768 tokens natively, and most can be extended to 131,072 tokens using YaRN rope scaling techniques.
Dense models
Model
Parameters
Layers
Attention Heads
Context Length
Qwen3-0.6B
0.6B (0.44B non-embedding)
28
16 for Q, 8 for KV
32,768
Qwen3-1.7B
1.7B (1.4B non-embedding)
28
16 for Q, 8 for KV
32,768
Qwen3-4B
4.0B (3.6B non-embedding)
36
32 for Q, 8 for KV
32,768
Qwen3-8B
8.2B (6.95B non-embedding)
36
32 for Q, 8 for KV
32,768
Qwen3-14B
14.8B (13.2B non-embedding)
40
40 for Q, 8 for KV
32,768
Qwen3-32B
32.8B (31.2B non-embedding)
64
64 for Q, 8 for KV
32,768
Mixture of Experts (MoE) models
Model
Total Parameters
Activated Parameters
Layers
Attention Heads
Experts
Activated Experts
Context Length
Qwen3-30B-A3B
30.5B (29.9B non-embedding)
3.3B
48
32 for Q, 4 for KV
128
8
32,768
Qwen3-235B-A22B
235B (234B non-embedding)
22B
94
64 for Q, 4 for KV
128
8
32,768
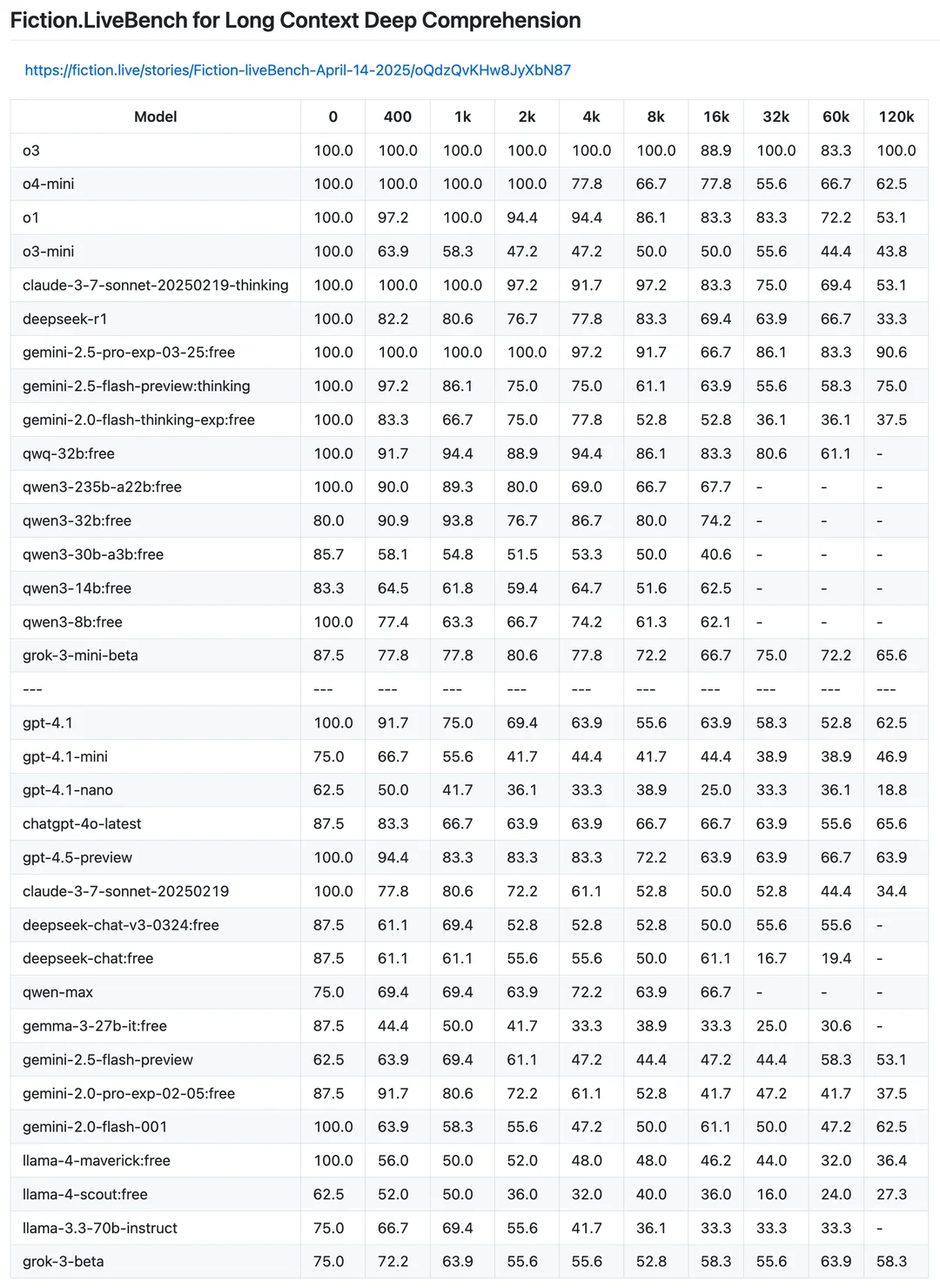
One area that Qwen is performing particularly well in is deep context comprehension. As a creative writer, this is something I personally pay quite a bit of attention to, as the ability to remember fine details is incredibly important. Humans intuitively know how to weight how important details are for writing, but this is a much harder task for an LLM. One interesting note discovered is that active parameters seem to matter the most for deep context, so if this is your goal the 32B dense model may actually outperform the 235B MoE model simply because it has more active params. However, both the MoE and dense Qwen models are performing quite well compared to the field on these tasks, competing against much larger models in the process (while outcompeting larger, previous-gen models like Llama3.)
Perhaps the most distinctive feature is Qwen3's ability to seamlessly switch between "thinking mode" (for complex reasoning, mathematics, and coding tasks) and "non-thinking mode" (for efficient general-purpose dialogue) within a single model. This hybrid approach allows better utilization of LLM capabilities and judicious use of tokens, with users able to control the "depth" of thinking - a first-of-its-kind feature that helps manage the balance between cost and quality.
What makes this mechanism particularly powerful is that it allows developers to allocate computational resources strategically based on task complexity. As noted in the Qwen team's blog post, "the integration of these two modes greatly enhances the model's ability to implement stable and efficient thinking budget control" with "scalable and smooth performance improvements that are directly correlated with the computational reasoning budget allocated."
This approach is innovative because it brings resource allocation decisions to the application level. For instance:
A customer service chatbot might use non-thinking mode for standard queries but switch to thinking mode when dealing with complex troubleshooting
A coding assistant could use thinking mode when reviewing or generating complex algorithms but switch to non-thinking mode for simple documentation tasks
A financial analysis tool might reserve thinking mode for investment scenarios requiring deep analysis while using non-thinking mode for basic account information queries
The benefit extends beyond just performance - it directly impacts operational costs. Since thinking mode consumes more computational resources and tokens, the ability to selectively engage it allows "applications to dynamically balance computational costs, latency, and response quality based on task complexity", giving developers more control over both the user experience and infrastructure expenses. This could be most directly realized in Runpod's serverless architecture, for example, where you are charged per second of GPU time.
API Parameters for Thinking Mode Control
When deploying Qwen3 models using popular serving frameworks like vLLM and SGLang, specific API parameters allow developers to control the thinking mode capabilities. Here's how to implement this control in different deployment scenarios:
vLLM Deployment
To serve a Qwen3 model with vLLM (version 0.8.5 or higher):
--enable-reasoning: Activates Qwen3's hybrid thinking capabilities within vLLM
--reasoning-parser deepseek_r1: Specifies how vLLM should interpret the model's thinking output format
This specific parser configuration is documented in the official Qwen documentation and vLLM GitHub repository, which confirm that Qwen3 models should use the DeepSeek R1 reasoning parser in vLLM deployments.
SGLang Deployment
For SGLang (version 0.4.6.post1 or higher):
Note that SGLang uses a different reasoning parser (qwen3) than vLLM.
Context limit
One point of note is that these models only have 32k context out of the box but can be extended to ~112k with YaRN, which differs from other new models that just have the context extended natively. Modifying Model Configuration Files
The simplest approach is to add the YaRN configuration directly to the model's config.json file:
This configuration extends the context window by a factor of 4, from 32K to 128K tokens. Note that there's not a free lunch here; there is a hit to perplexity when artificially extending context, whether it is YaRN, RoPE, or any other method. You also might consider using the unsloth quantizations instead which already have the extended context baked in.
What's new in Runpod Serverless: Faster cold starts, batch inference, and no-Docker deploys
Whether you're already running production endpoints on Runpod or you're sizing us up for the first time, here's a plain-language tour of what Runpod Serverless does today, why it's faster and cheaper than it was six months ago, and how to deploy your first endpoint in minutes.
Beyond the Notebook: The Engineering Realities of Production AI Agents
Shift from stateless inference to stateful architectures to resolve infrastructure bottlenecks like memory management, concurrency limits, and runaway jobs in production AI agents.


.jpeg)


