.jpeg)
Deploy When Available is now GA
Queue for any GPU spec, even one that's fully rented out, and we'll deploy it the moment capacity opens up. No more refreshing the console or running a sniping tool.
All
Blog
Learn how to run vLLM on Runpod’s serverless GPU platform. This guide walks you through fast, efficient LLM inference without complex setup.


vLLM is an open-source LLM inference and serving engine that utilizes a novel memory allocation algorithm called PagedAttention. It can run your models with up to 24x higher throughput than HuggingFace Transformers (HF) and up to 3.5x higher throughput than HuggingFace Text Generation Inference (TGI).
How does vLLM achieve this throughput improvement? Existing systems waste 60%-80% of the KV-Cache (LLM memory), whereas vLLM achieves near-optimal memory usage with a mere waste of under 4%. Because of this improved memory usage, we require fewer GPUs to achieve the same output, so the throughput is significantly higher than that of other inference engines.
Thousands of companies use vLLM to reduce inference costs. For example, LMSYS, the organization behind Chatbot Arena and Vicuna, cut the number of GPUs used to serve their growing traffic of ~45k daily requests by 50% while serving 2-3x more requests per second. vLLM leverages PagedAttention to reduce memory waste and achieve these efficiency improvements.
In early 2023, the authors behind vLLM noticed that existing inference engines only used 20%-40% of the available GPU memory. When exploring solutions to this problem, they remembered the concept of Memory Paging from operating systems. They applied it to better utilize KV-Cache, where transformers store attention calculations during LLM inference. Let's start with understanding Memory Paging.
In their paper, “Efficient Memory Management for Large Language Model Serving with PagedAttention,” the authors introduce PagedAttention, a novel algorithm inspired by virtual memory paging. Memory paging is used in operating systems, including Windows and Unix, to manage and allocate sections of a computer's memory, called page frames. It allows for more efficient memory usage by swapping out parts of memory that are not actively used. PagedAttention adapts this approach to optimize how memory is used in LLM serving, enabling more efficient memory allocation and reducing waste.



Have you noticed that the first few tokens returned from an LLM take longer than the last few? This effect is especially pronounced for longer prompts due to how LLMs calculate attention, a process heavily reliant on the efficiency of the Key-Value (KV) Cache.
The KV Cache is pivotal in how transformers process text. Transformers use an attention mechanism to determine which parts of the text are most relevant to the current tokens generated. This mechanism compares a newly generated query vector (Q) against all previously stored key vectors (K). Each key vector corresponds to earlier context the model considers, while each value vector (V) represents how important these contexts are in the current computation.

Instead of re-calculating these KV pairs for each new token generation, we append them to the KV cache so they can be reused in subsequent calculations.

The Cache is initially empty, and the transformer needs to precompute it for the entire sequence to start generating new tokens. This explains the slow speed of the first few tokens. However, traditional implementations of KV cache waste a lot of space.
PagedAttention addresses these inefficiencies through a more dynamic memory allocation using the previously unused space. Let's understand how existing systems waste memory space.
The parameters of a 13B LLM like llama-13b take up about 26GB. For an A100 40GB GPU, this already takes up 65% of its memory. We now only have about 30% of the memory for managing the KV Cache.
Existing systems store KV cache pairs in continuous memory spaces. In other words, they allocate a fixed, unbroken block of space for every request. However, requests to an LLM can vary in size widely, which leads to a significant waste of memory blocks.
The researchers behind vLLM break this down further into three types of memory waste:
As a result, only 20-40% of the KV cache being used to store token states.
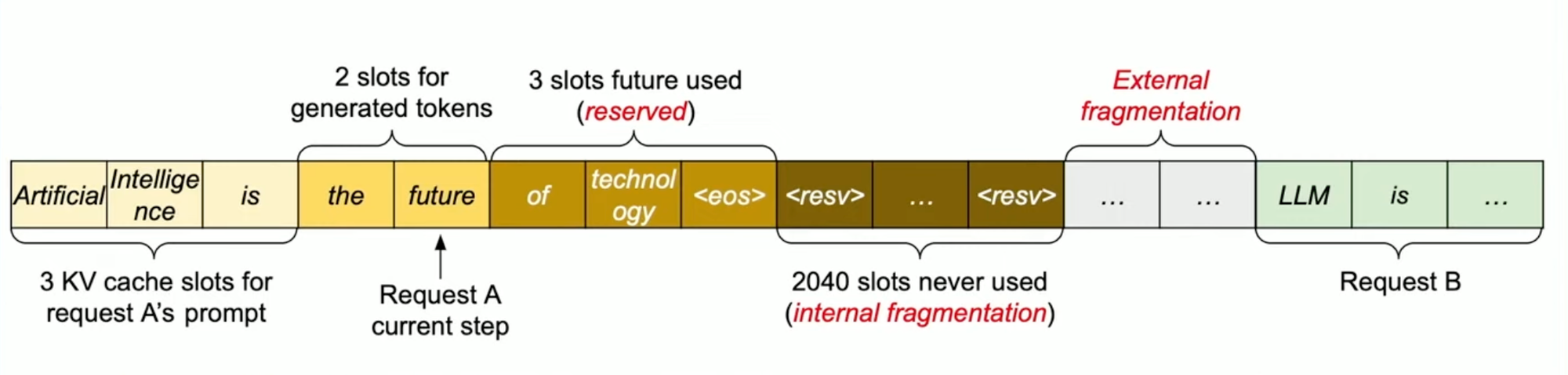
This continuous or fixed memory space allocation can suffice if the input and output lengths are static and known but is inefficient if the sequence lengths are dynamic, as is the case with most LLM inference use cases.
PagedAttention applies the concept of Memory Paging to more efficiently manage the KV Cache. It allocates blocks dynamically, enabling the system to store continuous blocks in arbitrary parts of the memory space. They are allocated on demand. The mapping between the logical KV cache and the physical memory space is stored in the Block table data structure.

With PagedAttention, vLLM eliminates external fragmentation—where gaps between fixed memory blocks go unused—and minimizes internal fragmentation, where allocated memory exceeds the actual requirement of the sequence. This efficiency means nearly all allocated memory is effectively used, improving overall system performance.
While previous systems waste 60%-80% of the KV cache memory, vLLM achieves near-optimal memory usage with a mere waste of under 4%.
The enhanced memory efficiency achieved through PagedAttention allows for larger batch sizes during model inference. This allows for more requests to be processed simultaneously and means that GPU resources are used more completely and efficiently, reducing idle times and increasing throughput.

Another advantage of PagedAttention's dynamic block mapping is memory sharing between separate requests and their corresponding sequences.

Let's look at two LLM-inference decoding algorithms where this memory sharing helps us:


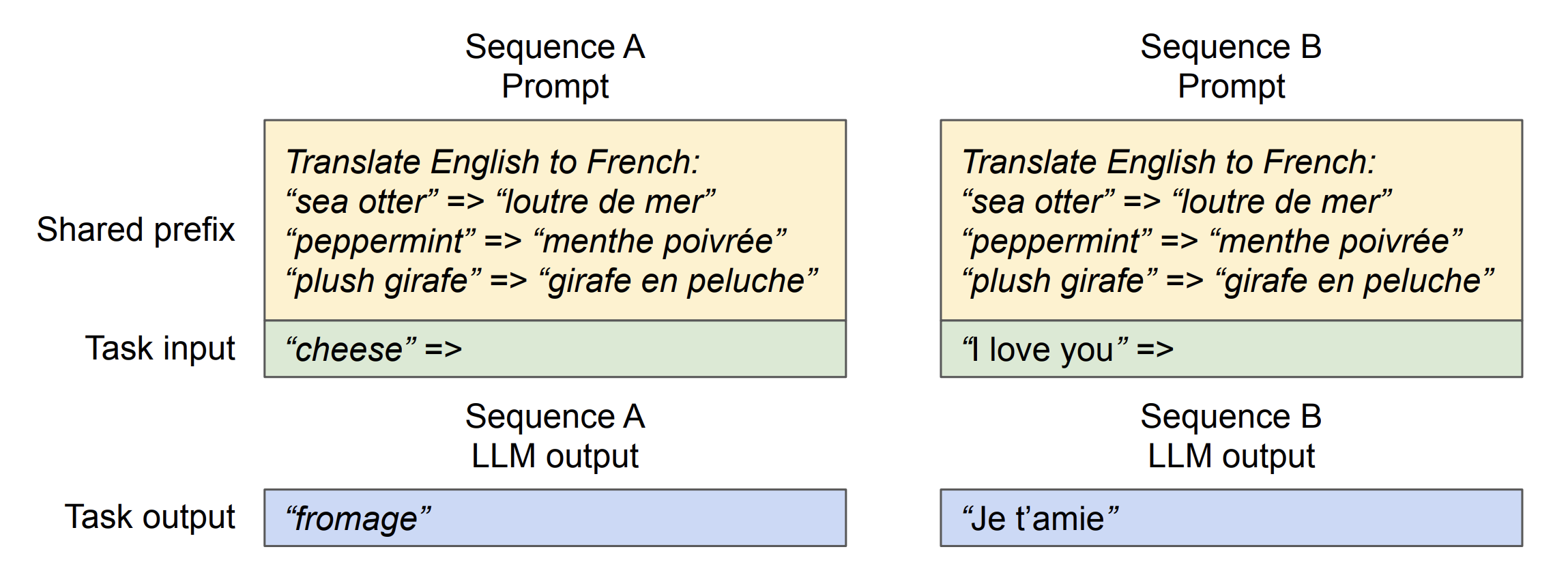
vLLM implements several other techniques to increase performance:
8-bit quantization reduces the precision of the model's numerical data from the standard 32 bits to just 8 bits. Applying this technique to a large model like Llama 13B, for example, which initially requires 52 GB in a 32-bit format (13b*32 bits = 13b*4 bytes = 52GB), would now only need 13 GB post-quantization.
This reduction in size allows models to fit better in memory, enabling a model like Llama 13B to run on a single 24 GB VRAM GPU. The process usually comes at the expense of some performance loss, but the tradeoff is worth the performance bump for many LLM inference use cases.
Improves efficiency by caching repeated computation across different inference requests, particularly beneficial in scenarios with repeated prompts, including multi-round conversations.

Speculative decoding is when a smaller model is used to predict the output of a larger model, thus inferring responses more quickly and potentially doubling decoding speeds.
Facilitates using Low-Rank Adaptation (LoRA) to manage multiple model adaptations efficiently. This allows a single base model to be used with various adapters, optimizing memory usage and computational efficiency across different tasks. An adapter, in this context, is a small, lower-rank matrix that fine-tunes the model on specific tasks without extensive retraining, enhancing versatility and resource efficiency.
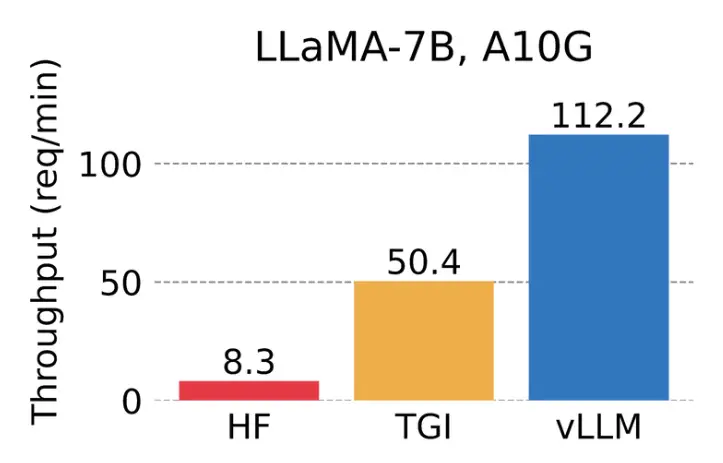
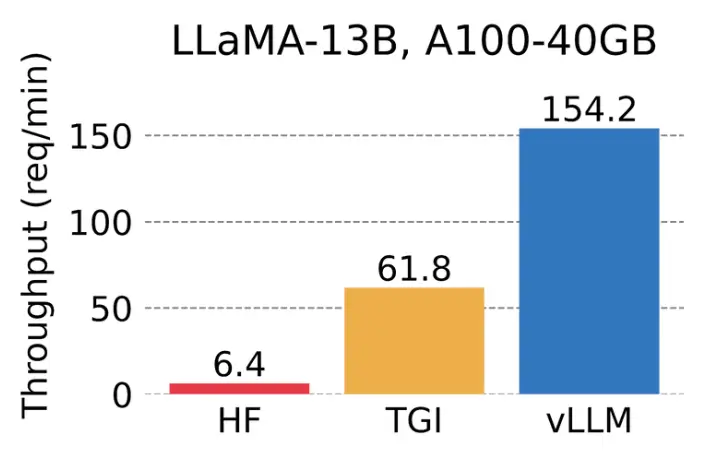
The Berkeley researchers behind vLLM compared the throughput of LLaMA-7B on an NVIDIA A10G GPU and LLaMA-13B on an NVIDIA A100 GPU (40 GB). vLLM achieves 24x higher throughput compared with HuggingFace Transformers (HF) and a 3.5x higher throughput compared with HuggingFace Text Generation Inference (TGI).
A direct performance comparison with TensorRT-LLM is difficult as the effectiveness of each can vary based on the model configuration, quantization precision, and specific hardware used. For instance, while vLLM demonstrates robust performance with AWQ quantization, TensorRT-LLM can leverage fp8 precision, optimized for NVIDIA's latest H100 GPUs, to enhance performance.
That said, we can compare the setup time and complexity of these two inference engines:
vLLM supports the most popular open-source LLMs on HuggingFace, including:
You can find a complete list in the vLLM supported models list.
Since July 2023, vLLM has rapidly gained over 20,000 GitHub stars and has a thriving community of 350+ open-source contributors.

Today, thousands of developers use vLLM to optimize their inference, and notable companies like AMD, AWS, Databricks, Dropbox, NVIDIA, and Roblox support it. The University of California, Berkeley, and the University of California, San Diego also directly support the project.
With help from the vLLM team at Berkeley, Runpod has built vLLM support into their Serverless platform so you can spin up an API endpoint to host any vLLM-compatible model.
To get started, follow these steps:
vLLM on Runpod enhances model efficiency and provides substantial cost savings, making it an excellent choice for startups scaling their LLM applications to millions of inference requests.
If you'd like to learn more about Runpod or speak with someone on the team, you can book a call from our Serverless page.
Thanks for reading! If you want to try vLLM in a cloud GPU environment, check out Runpod Serverless.
Deploy vLLM In Serverless Today
Author profile: Moritz Wallawitsch
Blog Posts
Queue for any GPU spec, even one that's fully rented out, and we'll deploy it the moment capacity opens up. No more refreshing the console or running a sniping tool.

Explore why faster chips have shifted the bottleneck to AI infrastructure, and what that means for teams running production workloads.
.jpeg)
With MIG, we can partition RTX 6000 Pro cards into isolated 24 GB instances. Here's when it makes sense for your workloads.
