.jpeg)
Deploy When Available is now GA
Queue for any GPU spec, even one that's fully rented out, and we'll deploy it the moment capacity opens up. No more refreshing the console or running a sniping tool.
All
Blog
Runpod’s serverless platform continues to evolve, especially for LLM workloads. Learn what’s new in 2025 and how to make the most of fast, scalable deployments.

.webp)
Out of all of the use cases that our serverless architecture has, LLMs are one of the best examples of it. Because so much of LLM use is dependent on the human using it to process, digest, and type a response, you save so much on GPU spend by ensuring that you only pay for the inference time rather than an entire pod – why continue to spend for GPU time when it's just going to sit idle? Not only that, but serverless allows you to scale seamlessly up to spikes in demand with a minimum of fuss. We are leaning hard into serverless and want to share what we've created with you.
We've cooked up a bunch of improvements designed to reduce friction and make the platform easier to use. Here's a roundup of what's come out over the last few months:
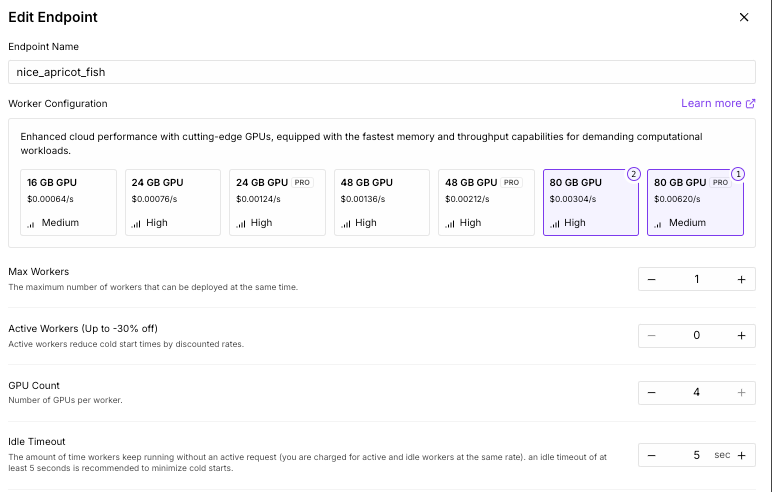
Without support involvement, you can now create workers with up to four GPUs for 80GB and 80GB Pro specs, up from two. This will give you up to 320GB to play with, which should be enough for most LLM use cases, except for Deepseek v3 and some higher bit quantizations of other large models. If you require more than 320GB, feel free to contact our friendly support team for an increase so you can get up to eight 80GB GPUs in your endpoint.
You can make the edits under the Edit Endpoint screen under GPU Count:
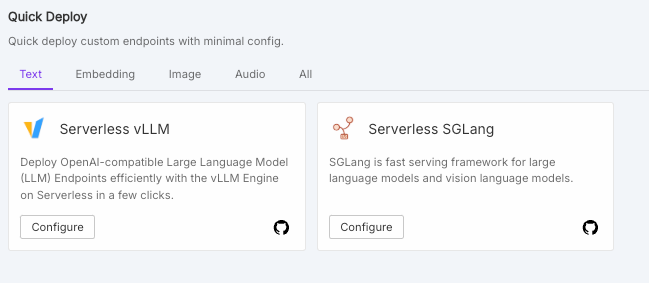
The Quick Deploy for VLLM doesn't look quite so lonely anymore with an SGLang option next to it.
SGLang is a specialized framework focused on structured generation and control flow, with features like:
vLLM emphasizes high-performance inference with features like:
The choice between them often depends on your specific needs. If you're primarily doing structured generation with complex control flows in Python, SGLang's native integration might be more convenient. If you're optimizing for maximum throughput in production, vLLM's performance optimizations could be more valuable.
We've written about SGLang and vLLM in the past if you've like to read more.
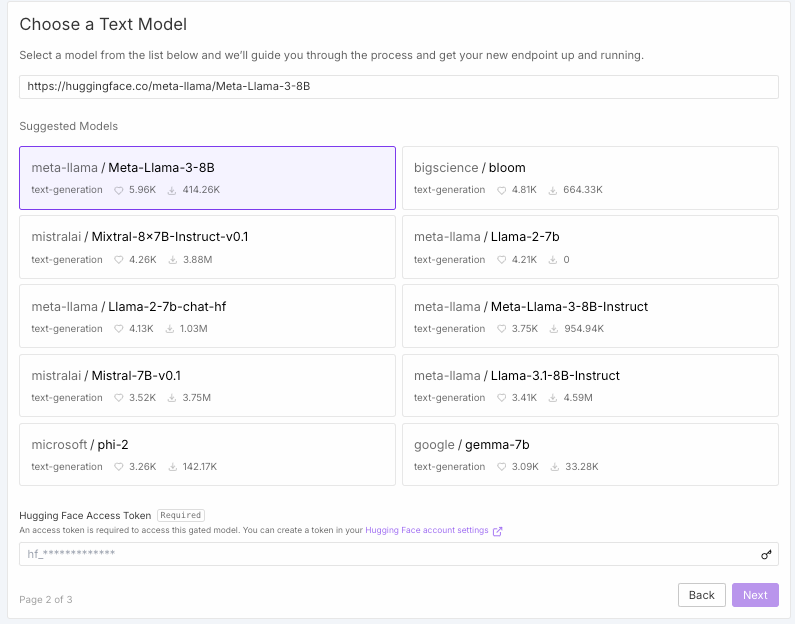
When deploying an endpoint, you can select a model from a list to pull straight from Huggingface, or enter the path for your preferred model to have it pulled instead - no more fiddling with environment variables if you'd rather not.
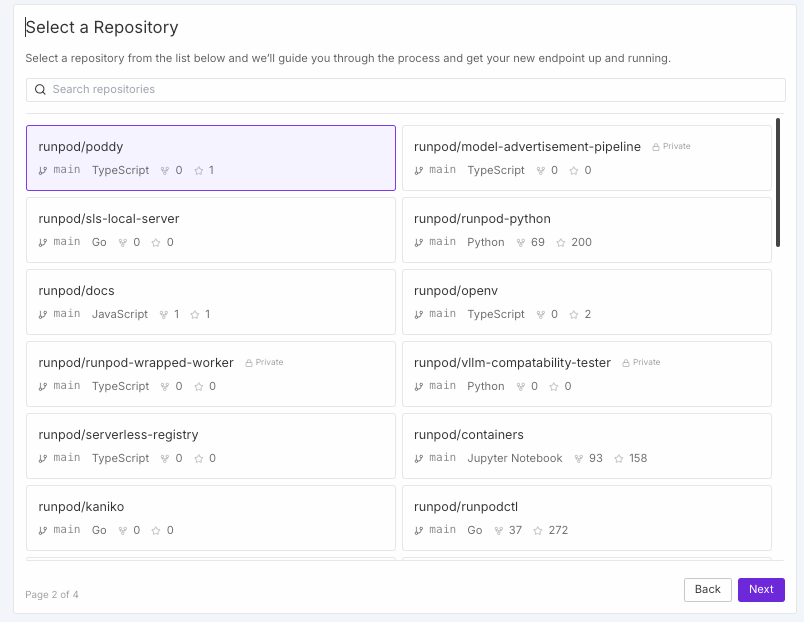
Want to bring your own inference engine instead? If it's in a GitHub repo, you can just bring it straight in with our new integration. Docker deploy isn't going anywhere, of course, but deploying straight from GitHub could save an enormous amount of middleman effort from having to bake and upload your own image.
Create a Serverless Endpoint Today
We're not done yet - we've got several more features working its way through the pipeline to make deploying serverless endpoints faster and easier to help support your team. Have any questions on how to use any of these features? Check out our Discord or drop us a line!
Author profile: Brendan McKeag
Blog Posts
Queue for any GPU spec, even one that's fully rented out, and we'll deploy it the moment capacity opens up. No more refreshing the console or running a sniping tool.

Explore why faster chips have shifted the bottleneck to AI infrastructure, and what that means for teams running production workloads.
.jpeg)
With MIG, we can partition RTX 6000 Pro cards into isolated 24 GB instances. Here's when it makes sense for your workloads.
