Everyone's arguing about whether to scale up or out these days, and the pressure's never been higher. With AI workloads eating up resources like candy, microservices everywhere, and users scattered across the globe, that little app you deployed with modest resources is probably screaming for help right about now.
Here's the thing - when your usage starts spiking and performance tanks, you need to figure out how to scale, and fast. The choice between throwing more power at your existing servers versus spreading the load across multiple machines isn't just a technical decision anymore. It's what separates the companies that handle growth gracefully from those that crash and burn when opportunity knocks.
Table of Contents
- Fundamental Scaling Concepts
- Implementation Strategies and Best Practices
- Technology-Specific Scaling Considerations
- Making the Right Scaling Decision
- Final Thoughts
TL;DR
- Scaling up adds more power to existing machines (CPU, RAM, storage), while scaling out distributes workload across multiple machines
- Scale up typically reduces latency but limits throughput; scale out increases throughput but may introduce latency challenges
- Initial investment differs dramatically - scale up requires significant upfront hardware costs, scale out allows gradual investment scaling
- Your application architecture determines which approach works best - some apps can't effectively utilize multiple cores, others thrive in distributed environments
- Modern infrastructure often benefits from hybrid approaches, combining both strategies for optimal performance and cost-effectiveness
- Cloud platforms and serverless architectures are evolving traditional scaling paradigms, offering automatic resource allocation based on demand
Fundamental Scaling Concepts
Look, before you start throwing money at servers or spinning up container clusters, you need to understand what you're actually dealing with. The difference between scaling up and scaling out isn't just academic - it's going to shape every infrastructure decision you make from here on out.
Think of scaling up like souping up your car - you're adding a bigger engine, more horsepower. Scaling out is like adding more cars to your fleet. Both get you where you need to go, but the approach is totally different, and so are the costs, complexity, and headaches that come with each.
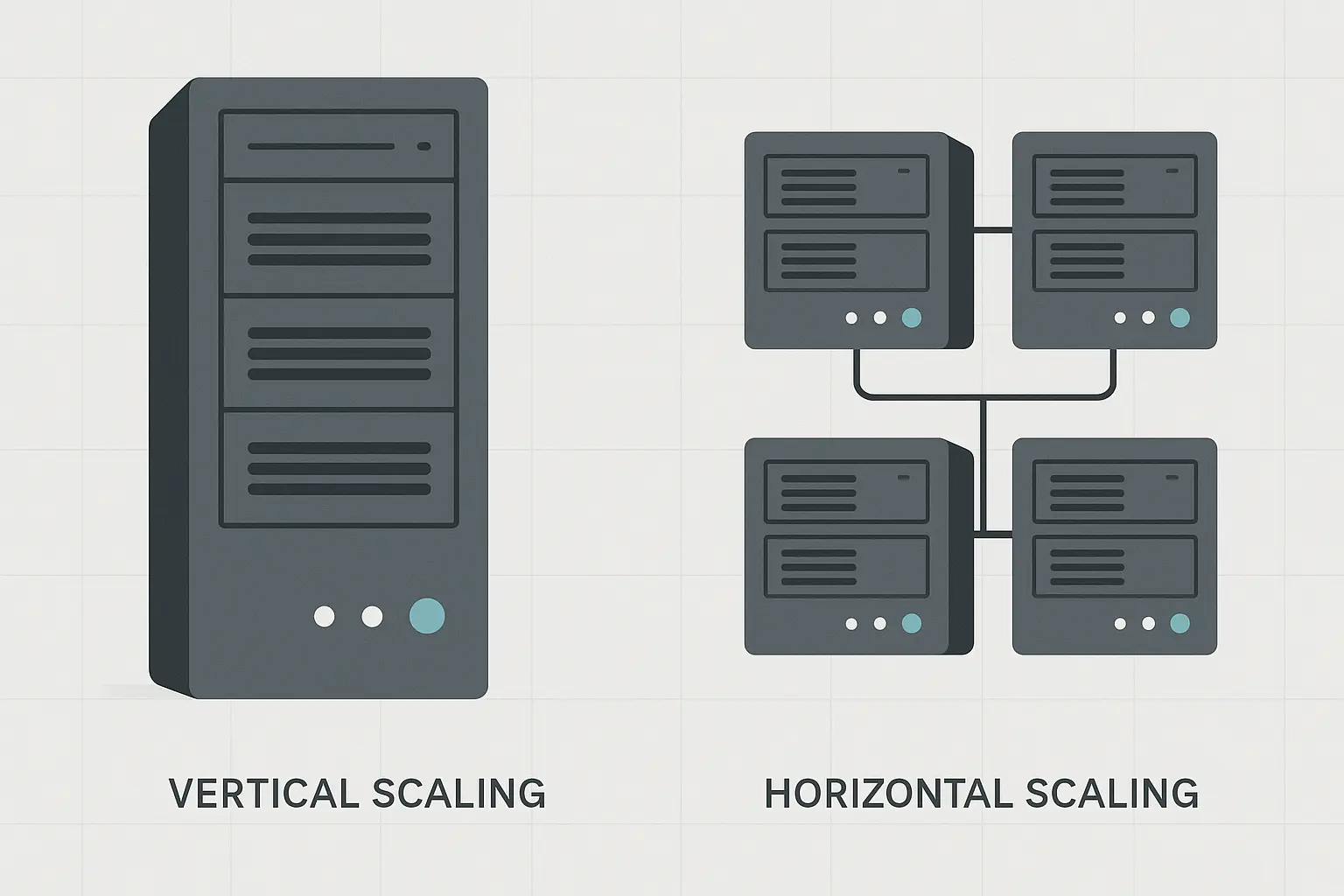
Defining Scale Up and Scale Out
We've all been there - your app is crawling, users are complaining, and your boss is breathing down your neck. The temptation is to throw money at the biggest server you can find. Sometimes that works. Sometimes you just bought an expensive paperweight.
Vertical Scaling (Scale Up) Mechanics
Scale up means boosting the power of your existing machines. You're adding more CPU cores, increasing RAM capacity, or expanding storage within a single server instance.
When your database starts hitting memory limits, you might double the RAM from 32GB to 64GB. When processing becomes sluggish, you could upgrade from 8 cores to 16 cores. Sounds straightforward, right? Well, there's more complexity under the hood than most people realize.
Your operating system needs to recognize and utilize the additional resources. Applications must be designed to take advantage of extra cores or memory. Last year, I watched a startup blow $15K on a monster CPU upgrade, only to realize their legacy PHP app couldn't use more than one core. The CEO wasn't happy when we had to explain that one.
Horizontal Scaling (Scale Out) Architecture
Scaling out takes a completely different approach. Instead of making individual machines more powerful, you're creating a network of interconnected systems that work together.
Your workload gets distributed across multiple machines. Each server handles a portion of the total demand. When traffic increases, you add more servers to the pool rather than upgrading existing ones.
But here's the catch - this approach requires sophisticated coordination. Load balancers distribute incoming requests. Data synchronization becomes critical. Service discovery mechanisms help different components find and communicate with each other. The architecture becomes inherently more complex, but you gain flexibility and resilience.
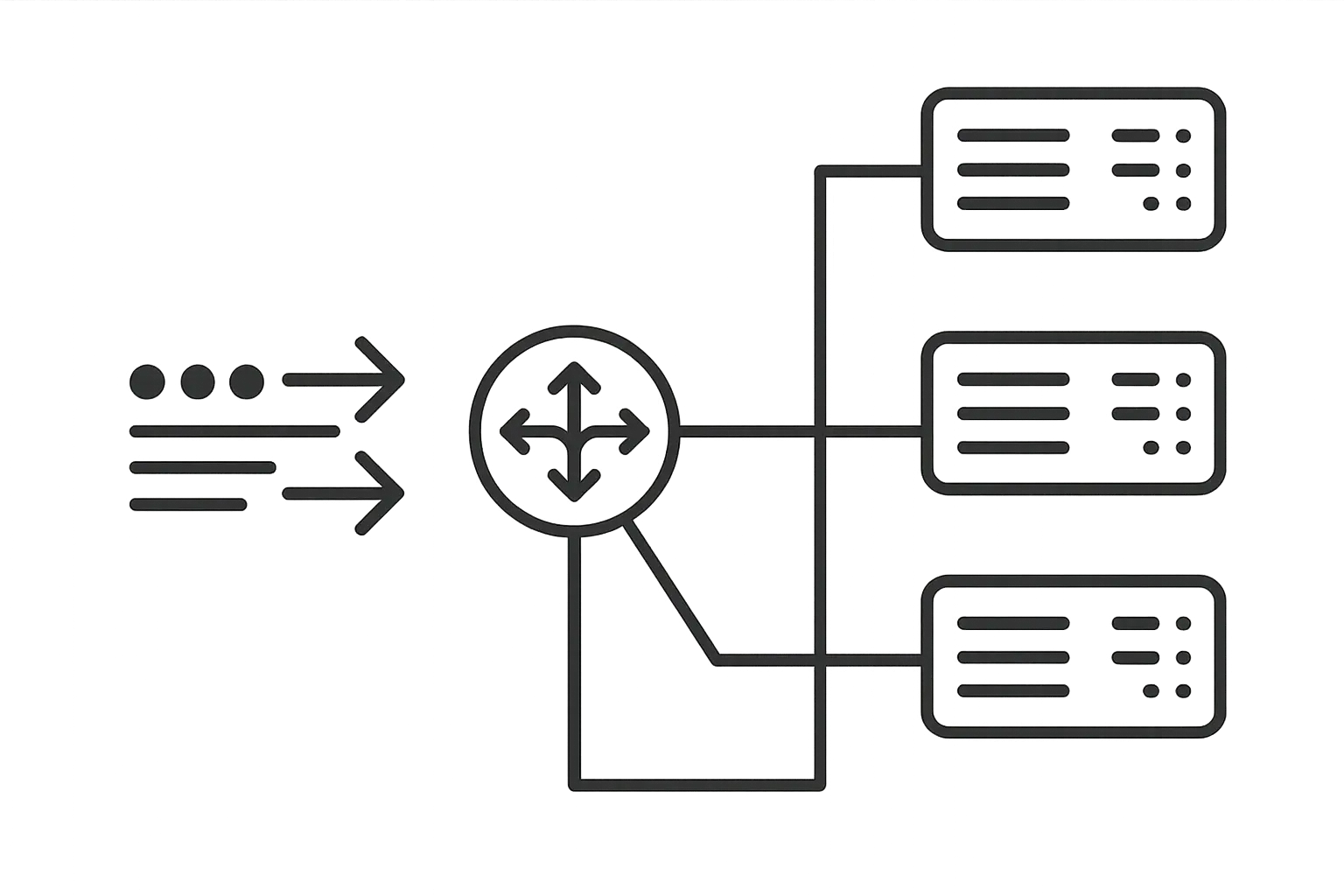
Resource Allocation Paradigms
Here's where it gets interesting - different scaling approaches demand totally different resource management strategies. Scale up focuses on maximizing utilization within a single machine. You're optimizing memory allocation, CPU scheduling, and I/O operations for peak efficiency on one system.
Scale out requires distributed resource management. Memory allocation happens across multiple machines. Network bandwidth becomes a critical consideration. Data locality affects performance significantly - you want related data and processing to happen on the same node when possible.
These paradigms affect everything from how you design your applications to how you monitor system health. Scale up monitoring focuses on individual machine metrics. Scale out monitoring requires cluster-wide visibility and understanding of inter-node communication patterns.
Performance and Capacity Considerations
Let's talk about what really matters - how fast your stuff runs and how much it can handle. Each scaling strategy delivers different performance characteristics, and understanding these trade-offs is crucial before you make any decisions.
The reality is that scale up typically reduces latency but may limit throughput, while scale out can increase throughput but introduces latency challenges. Knowing where your bottlenecks actually are helps determine whether vertical or horizontal scaling will be more effective for your specific situation.
Throughput vs Latency Trade-offs
Scale up generally wins on latency. When all your processing happens on a single, powerful machine, there's no network communication delay between components. Data doesn't need to travel across network connections. Everything operates within the same memory space and CPU cache hierarchy.
However, throughput can hit walls with vertical scaling. Even the most powerful single machine has limits. You can only add so many CPU cores before diminishing returns kick in. Memory bandwidth becomes a bottleneck. Single points of failure become more critical as you concentrate more workload on fewer machines.
Scaling out excels at throughput. You can theoretically add unlimited machines to handle more concurrent requests. Each new server increases your total processing capacity. Workload distribution means you're not constrained by the limits of any single machine.
But wait, there's a catch - latency suffers in distributed systems. Network communication introduces delays. Data might need to be fetched from remote nodes. Coordination between services adds overhead. The more distributed your system becomes, the more these latency penalties accumulate.
| Performance Metric | Scale Up (Vertical) | Scale Out (Horizontal) |
|---|---|---|
| Latency | Lower – no network overhead | Higher – network communication delays |
| Throughput | Limited by single machine capacity | Virtually unlimited with more nodes |
| Memory Access | Shared memory space, faster | Distributed memory, network dependent |
| Processing Limits | Hardware ceiling per machine | Scales with number of machines |
| Network Overhead | Minimal internal communication | Significant inter-node communication |
| Failure Impact | Single point of failure | Distributed failure tolerance |
Bottleneck Identification Patterns
Recognizing bottlenecks helps you choose the right scaling strategy, and honestly, this is where most teams mess up. I can't tell you how many times I've seen teams monitoring CPU usage and thinking "we need more cores!" when their database was actually choking on disk I/O.
CPU-bound applications often benefit from scale up - adding more cores to the same machine can provide immediate relief. Memory-intensive workloads might see dramatic improvements from RAM upgrades.
I/O bottlenecks present interesting challenges. Database queries hitting storage limits might benefit from faster SSDs (scale up) or distributed databases (scale out). Network-bound applications usually favor horizontal scaling since you can distribute network load across multiple interfaces.
Application architecture plays a huge role in bottleneck patterns. Monolithic applications with shared state often can't effectively utilize scale out approaches. Microservices architectures naturally align with horizontal scaling strategies.
E-commerce Platform Bottleneck Analysis: A growing e-commerce platform experiencing slow page loads during peak shopping periods conducted a bottleneck analysis. They discovered their product catalog database was hitting memory limits during high-traffic events. Initial analysis showed 95% memory utilization but only 60% CPU usage during peak loads. The team chose vertical scaling, upgrading from 32GB to 128GB RAM on their primary database server. This single change reduced query response times from 2.3 seconds to 400 milliseconds during peak traffic, demonstrating how proper bottleneck identification leads to effective scaling decisions.
Cost Analysis Framework
Let's talk money for a second. That enterprise-grade server? It's not just expensive - it's "explain to your CFO why you need a second mortgage" expensive. The financial implications of scaling decisions extend far beyond initial hardware costs to include operational expenses, maintenance, and opportunity costs.
Scale up often requires significant upfront investment in high-end hardware, while scale out allows for more gradual investment scaling. Understanding different operational expense models and ROI timelines is crucial for long-term financial planning and budget allocation decisions.
Initial Investment Requirements
Scale up demands significant upfront capital. High-end servers with maximum CPU cores, RAM, and storage capacity cost substantially more than their mid-range counterparts. The relationship isn't linear - doubling performance often triples or quadruples the price.
Enterprise-grade hardware comes with premium pricing. ECC memory, redundant power supplies, and high-performance storage arrays add considerable cost. You're essentially betting on future growth by purchasing capacity you might not immediately need.
Scaling out spreads investment over time. You can start with commodity hardware and add more servers as demand grows. Initial costs are lower since you're buying standard components rather than premium configurations. This approach aligns spending with actual growth rather than projected growth.
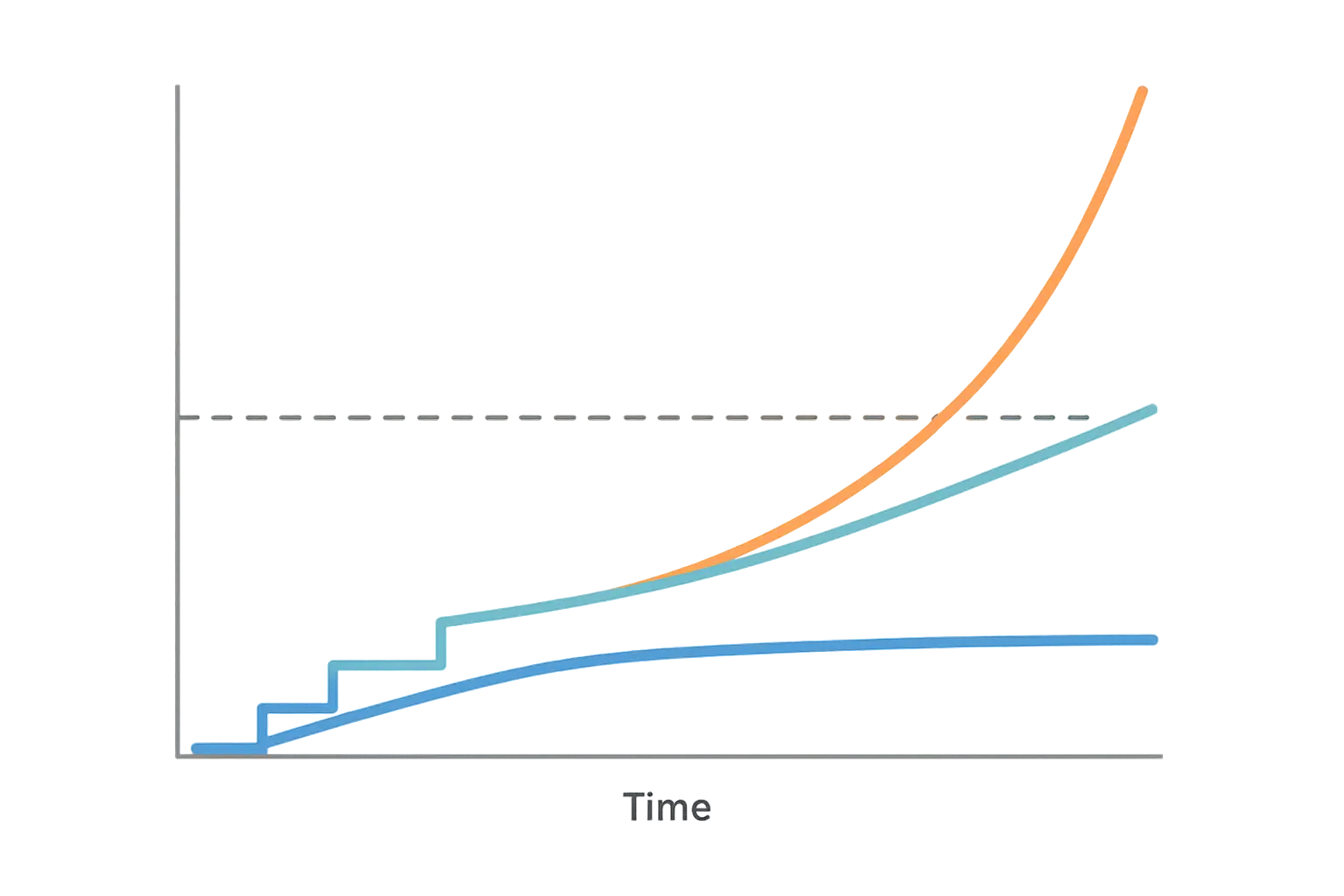
Operational Expense Models
Ongoing costs vary dramatically between approaches. Scale up typically has lower complexity costs - fewer machines mean less management overhead. You're maintaining fewer operating systems, applying fewer security patches, and monitoring fewer individual components.
But hardware replacement expenses hit harder with vertical scaling. When a high-end server fails, replacement costs are substantial. Downtime impact is more severe since you're losing a larger portion of your total capacity.
Scale out distributes operational complexity. You're managing more individual machines, which increases administrative overhead. However, individual hardware failures have less impact. Commodity hardware is cheaper to replace, and redundancy is built into the architecture.
Power and cooling costs also differ. A few high-performance servers might consume less total power than many commodity servers providing equivalent capacity. Data center space utilization becomes a factor - rack density affects your hosting costs.
ROI Timeline Considerations
Different scaling strategies show varying return on investment timelines, and this is where things get really interesting from a business perspective. Scale up often provides immediate performance improvements but requires large upfront investments that take time to justify. You're essentially pre-paying for future capacity.
The ROI calculation becomes complex when you factor in opportunity costs. Money spent on high-end hardware today can't be invested in other business priorities. If growth projections don't materialize, you're stuck with expensive, underutilized resources.
Scale out offers more flexible ROI profiles. You can invest incrementally as revenue grows. Each new server addition can be justified by immediate demand rather than projected future needs. This approach reduces financial risk but might result in higher long-term costs if you're constantly adding capacity.
As you add compute resources to a physical server, it is difficult to increase and balance the performance linearly for all the components, and you will most likely hit a bottleneck somewhere. For example, a given server may have a memory bottleneck with 100% memory usage and 70% CPU usage. After doubling the number of DIMMs, you now have 100% of CPU usage vs 80% of memory usage.
Implementation Strategies and Best Practices
Alright, enough theory. Let's talk about actually doing this stuff without breaking everything in production. Successfully implementing scaling strategies requires careful planning, proper tooling, and adherence to proven methodologies - but more importantly, it requires not panicking when things don't go exactly as planned.
We'll cover the practical aspects of executing scaling decisions effectively, from pre-scaling assessments and hardware upgrade execution for vertical scaling, to load distribution mechanisms and service orchestration for horizontal scaling.
Scale Up Implementation Steps
Before throwing more hardware at performance problems, you need to understand what's actually causing the bottlenecks. I can't tell you how many times I've seen teams monitoring CPU usage and thinking "we need more cores!" when their database was actually choking on disk I/O.
Pre-Scaling Assessment Process
Here's what I learned the hard way: collect baseline metrics during both normal operations and when everything's on fire. CPU utilization tells you one story, but response times tell you what users actually experience. Queue depths? That's where you see the real pain points.
Start by collecting baseline metrics during normal operations and peak usage periods. CPU utilization, memory consumption, disk I/O rates, and network throughput all tell part of the story. But you also need application-level metrics - response times, queue depths, and error rates.
Real talk on pre-scaling assessment:
- Monitor current resource utilization patterns over time
- Identify peak usage periods and resource constraints
- Analyze application performance metrics
- Determine if the application can effectively utilize additional resources
The last point is crucial. Some applications can't effectively use additional CPU cores due to single-threaded bottlenecks. Others might not benefit from extra RAM if they're designed with small memory footprints. I once worked with a team that bought a 32-core monster to speed up their data processing pipeline. Turns out their Python script was single-threaded and couldn't use more than one core. We basically bought the world's most expensive space heater.
Hardware Upgrade Execution
The hardware upgrade part is where things get stressful. Nobody wants to be the person who brought down production during a "simple" RAM upgrade. Planning becomes critical.
Scheduling maintenance windows during low-traffic periods minimizes user impact. But "low-traffic" periods are becoming rare as applications serve global audiences. You might need to implement rolling upgrades or blue-green deployments to maintain availability.
Steps to take:
- Schedule maintenance windows during actual low-traffic periods
- Create comprehensive backups of system state and data
- Test upgrade procedures in staging environments first
- Implement monitoring to verify performance improvements post-upgrade
Testing upgrade procedures in staging environments catches issues before they affect production. But staging environments rarely match production complexity perfectly. Load testing with realistic traffic patterns helps validate that upgrades will perform as expected.
Create backups of everything. Test your upgrade procedures on staging first. And please, monitor everything after the upgrade to make sure it actually helped. If your performance metrics don't improve significantly, you might have other bottlenecks lurking.
Scale Out Deployment Architecture
Horizontal scaling demands sophisticated architectural planning to ensure system cohesion and optimal performance distribution. This involves implementing robust load balancing strategies, managing data consistency across distributed systems, and leveraging orchestration tools to handle complexity.
Load Distribution Mechanisms
Load balancing sounds straightforward until you realize your application has session state scattered everywhere. Effective scale out implementations require robust load balancing strategies. Traffic distribution across multiple instances determines whether your horizontal scaling actually improves performance or creates new bottlenecks.
Simple round-robin load balancing works great in theory, but real apps are messier than that. Each request goes to the next server in rotation. But real-world applications often have varying processing complexity and server capabilities.
Weighted load balancing accounts for different server capacities. More powerful servers receive proportionally more traffic. Health checks ensure traffic doesn't route to failed or overloaded instances.
I've seen plenty of teams implement "perfect" load balancing only to discover their users keep getting logged out because session data lives on specific servers. Session affinity (sticky sessions) becomes necessary when applications maintain server-side state. Users need to consistently reach the same server to maintain their session data. This approach limits load distribution flexibility but maintains application functionality.
Meta's recent infrastructure developments demonstrate the scale of modern distributed systems. Meta's Backbone network has evolved to handle unprecedented growth, with their Express Backbone (EBB) network showing exponential traffic increases since 2015. Their 10X Backbone initiative uses both scaling up techniques (more powerful individual components) and scaling out approaches (distributed metro architecture) to handle the massive interconnection requirements of modern data centers.
Data Consistency Management
Data consistency across multiple systems? That's where things get really interesting. When data gets distributed across multiple nodes, ensuring consistency becomes complex.
Strong consistency requires coordination between nodes before confirming data writes. This approach guarantees data accuracy but introduces latency and reduces availability during network partitions.
Eventual consistency allows nodes to operate independently and synchronize data asynchronously. This approach improves performance and availability but means data might be temporarily inconsistent across nodes.
For a banking app, you probably want strong consistency. For a social media feed? Users won't notice if their friend's latest lunch photo takes an extra second to appear everywhere.
Service Orchestration Frameworks
Modern scale out architectures rely on orchestration tools to manage complexity. Container orchestration platforms handle deployment, scaling, and management of distributed applications automatically.
Modern orchestration tools handle a lot of the complexity: Container platforms like Kubernetes manage service discovery automatically. Your services find each other without you having to hardcode IP addresses everywhere. They manage rolling updates, ensuring new versions deploy without service interruption.
Auto-scaling capabilities monitor system metrics and automatically add or remove instances based on demand. But here's the thing - all this automation is only as good as the metrics you're monitoring and the thresholds you set. Scale too aggressively and you're burning money on unused resources. Scale too conservatively and you're back to angry users and performance problems.
Microservices Auto-Scaling Implementation: A SaaS company migrated their monolithic application to microservices architecture and implemented Kubernetes-based auto-scaling. Their user authentication service automatically scales from 3 to 15 pods during peak login hours (8-10 AM), while their reporting service scales up during end-of-month periods when customers generate analytics reports. The implementation uses CPU utilization (70% threshold) and custom metrics (queue depth) to trigger scaling events. This approach reduced infrastructure costs by 35% during off-peak hours while maintaining 99.9% uptime during traffic spikes.
Technology-Specific Scaling Considerations
Different technologies and use cases require tailored scaling approaches, and honestly, this is where a lot of teams get tripped up. What works for your web servers might be completely wrong for your storage systems or AI workloads.
We'll examine scale-out NAS and storage solutions that leverage distributed file systems, as well as cloud and virtualized environments that offer unique advantages through auto-scaling and serverless paradigms.
Scale-Out NAS and Storage Solutions
Storage scaling gets weird fast. Traditional storage systems hit walls pretty quickly - you can only make a single storage controller so powerful before physics gets in the way.
Distributed File System Architecture
Scale-out NAS systems fundamentally change how we think about storage. Instead of relying on one massive storage box, you've got a bunch of smaller ones working together.
Each node contributes storage capacity and processing power. Files get broken into chunks and distributed across the cluster. Metadata servers track where each piece of data lives. This architecture provides both capacity scaling (add more nodes for more storage) and performance scaling (more nodes mean more concurrent I/O operations).
Steps to implement:
- Design data distribution strategy across nodes
- Implement redundancy and fault tolerance mechanisms
- Configure network topology for optimal data access
- Establish monitoring and maintenance procedures
Data distribution strategies affect both performance and reliability. Some systems use consistent hashing to distribute data evenly. Others use policy-based placement that considers factors such as node performance, network topology, and data access patterns.
The trick is making sure data stays close to where it's needed. Network latency kills performance in distributed storage. Redundancy becomes critical in distributed storage. When data spreads across multiple nodes, individual node failures are inevitable. Replication strategies ensure data remains available even when nodes fail. Erasure coding provides space-efficient redundancy for less frequently accessed data.
Performance Optimization Techniques
Optimizing scale-out storage requires balancing multiple competing factors. Data locality affects performance significantly - accessing data from local storage is much faster than retrieving it over the network.
You want your frequently accessed data cached locally, not retrieved over the network every time. Caching strategies help improve performance for frequently accessed data. Each node can cache popular files locally. Distributed caching protocols ensure cache coherency across the cluster.
Network topology becomes crucial for performance. High-bandwidth, low-latency interconnects between storage nodes reduce the penalty of distributed data access. Network congestion can become a bottleneck that limits the benefits of adding more storage nodes.
Scale out architectures often allow for more gradual spending as you incrementally add commodity hardware. This approach can result in better overall cost efficiency, especially for large deployments. Additionally, scale out architectures can utilize cheaper hardware components, though they require more networking equipment and physical space.
Cloud and Virtualized Environments
Cloud environments make scaling decisions more flexible, but they also introduce new complexities around cost optimization and resource management. Modern cloud environments enable automatic scaling, container orchestration, and serverless paradigms that represent an evolution of traditional scaling principles.
Auto-Scaling Configuration
Auto-scaling groups are game-changers when configured properly. Modern cloud platforms enable automatic scaling based on predefined metrics. This capability combines benefits of both scaling approaches - you can scale up individual instances and scale out the number of instances automatically.
The system watches your metrics and automatically launches more instances when needed. But getting the triggers right takes some trial and error. Auto-scaling groups monitor metrics such as CPU utilization, memory usage, or custom application metrics. When thresholds are exceeded, the system automatically launches additional instances or increases the size of existing instances.
I've seen auto-scaling configurations that were so sensitive they'd spin up dozens of instances for minor traffic bumps. Others were so conservative they'd let the system burn before adding capacity. Configuration requires careful consideration of scaling triggers and cooldown periods. Scaling too aggressively can lead to resource waste and unnecessary costs. Scaling too conservatively might not handle traffic spikes effectively.
Container Orchestration Scaling
Containerized applications can leverage both vertical and horizontal scaling through sophisticated orchestration platforms. Kubernetes, for example, supports both horizontal pod autoscaling (adding more container instances) and vertical pod autoscaling (increasing resource limits for existing containers).
Kubernetes can scale both horizontally (more pods) and vertically (bigger pods) automatically. Horizontal pod autoscaling monitors metrics and automatically adjusts the number of running pods. This approach works well for stateless applications that can handle traffic distribution across multiple instances.
Vertical pod autoscaling adjusts CPU and memory limits for running containers based on actual usage patterns. This approach helps optimize resource utilization without requiring application architecture changes.
Serverless Scaling Paradigms
Serverless architectures represent an evolution of scale-out principles. The cloud provider automatically manages resource allocation based on demand. You don't need to provision servers or manage scaling policies.
Functions scale automatically from zero to thousands of concurrent executions. Each function invocation gets its own isolated execution environment. This approach provides ultimate scaling flexibility but introduces constraints around execution time limits and stateless operation requirements.
Serverless scaling works particularly well for event-driven workloads with variable demand patterns. You pay only for actual execution time rather than provisioned capacity.
The evolution of AI infrastructure is driving new scaling paradigms. Nvidia's vision as outlined by CEO Jensen Huang emphasizes that "there's no replacement for scaling up before you scale out" when building AI factories. Their Blackwell Ultra NVL72 platform demonstrates extreme scale-up architecture with 600,000 components per data center rack and 120 kilowatts of fully liquid-cooled infrastructure, representing what Huang calls "the most extreme scale-up the world has ever done."
Making the Right Scaling Decision
Your application architecture matters more than any performance benchmark you'll find online. Some apps are just built for vertical scaling - they can't effectively use multiple servers no matter how hard you try.
We'll explore a systematic decision matrix framework that analyzes application architecture, aligns with business requirements, and assesses risk profiles. We'll also examine hybrid scaling approaches that combine both strategies.
Decision Matrix Framework
A systematic approach to evaluating scaling options helps ensure decisions align with both technical requirements and business objectives. This involves analyzing your application's architecture, aligning scaling decisions with business growth projections, and conducting thorough risk assessments.
Application Architecture Analysis
Single-threaded applications are the obvious example, but state management is the real killer. If your app keeps a bunch of data in memory and different parts need to share it constantly, distributing across multiple servers becomes a nightmare.
Some applications are naturally suited for vertical scaling, while others thrive in distributed environments. Single-threaded applications can't effectively utilize additional CPU cores from vertical scaling. If your application processes requests sequentially, adding more cores won't improve performance. You'd need to redesign the application to support multi-threading or consider horizontal scaling instead.
Evaluation steps:
- Assess application's ability to utilize multiple cores/threads
- Evaluate state management and data sharing requirements
- Analyze communication patterns between application components
- Determine scalability bottlenecks in current architecture
State management becomes critical in scaling decisions. Applications that maintain extensive in-memory state are difficult to scale horizontally. Session data, caches, and shared variables create dependencies that complicate distribution across multiple machines.
Communication patterns reveal scaling constraints. Applications with tight coupling between components struggle with horizontal scaling due to increased network latency. Loosely coupled architectures with well-defined APIs scale out more effectively.
Business Requirement Alignment
Scaling decisions must align with business growth projections, budget constraints, and operational capabilities. Technical excellence means nothing if it doesn't support business objectives.
Business requirements should drive technical decisions:
Rapid, unpredictable growth usually means you want the flexibility of horizontal scaling. Steady, predictable growth might justify the upfront cost of vertical scaling. Growth rate projections affect scaling strategy selection. Rapid, unpredictable growth often favors horizontal scaling due to its flexibility. Steady, predictable growth might justify the upfront investment in vertical scaling.
Assessment criteria:
- Growth rate projections and timeline
- Budget availability for infrastructure investment
- Technical team capabilities and expertise
- Compliance and regulatory requirements
Your budget model matters too - can you afford the big upfront investment, or do you need to spread costs over time? Budget availability shapes scaling decisions significantly. Vertical scaling requires larger upfront investments but potentially lower operational complexity. Horizontal scaling spreads costs over time but increases operational overhead.
Don't forget about your team's capabilities. Managing distributed systems requires different skills than optimizing single-server performance. If your team has never dealt with service meshes and distributed debugging, maybe start with vertical scaling while you build those skills.
Risk Assessment and Mitigation
Each scaling approach carries different risk profiles. Understanding these risks helps you make informed decisions based on your organization's risk tolerance.
Risk tolerance varies by organization:
Vertical scaling puts more eggs in fewer baskets. When that high-end server fails, you lose a big chunk of capacity. But there are fewer moving parts, which means fewer things can break. Vertical scaling concentrates risk in fewer systems. When a high-performance server fails, you lose a significant portion of your capacity. However, the reduced complexity means fewer potential failure points overall.
Horizontal scaling spreads the risk but adds complexity. Individual server failures have less impact, but now you have network partitions, distributed system bugs, and coordination failures to worry about. Horizontal scaling distributes risk across multiple systems. Individual server failures have less impact, but the increased complexity introduces more potential failure modes. Network partitions, distributed system bugs, and coordination failures become new risk categories.
Decision FactorScale Up (Vertical)Scale Out (Horizontal)Application TypeMonolithic, single-threadedMicroservices, statelessGrowth PatternPredictable, steadyRapid, unpredictableBudget ModelHigh upfront, lower operationalLower upfront, higher operationalTeam ExpertiseTraditional system administrationDistributed systems, DevOpsRisk ToleranceLower complexity, higher impactHigher complexity, distributed riskCompliance NeedsSimpler audit trailsComplex distributed compliance
Hybrid Scaling Approaches
Most successful systems use both strategies strategically. Your database might scale vertically for consistency and performance, while your web tier scales horizontally for traffic handling.
Modern infrastructure often benefits from combining both scaling strategies, leveraging the strengths of each approach for optimal performance and cost-effectiveness.
Multi-Tier Scaling Architecture
Complex applications can benefit from scaling different tiers using different strategies. I worked on an e-commerce platform that used massive database servers for transaction processing but auto-scaled their web servers during traffic spikes. The database needed consistency and complex query performance. The web servers just needed to handle more concurrent users.
Database servers often benefit from vertical scaling. Relational databases with complex queries and transactions perform better with more powerful single machines. The overhead of distributed database coordination can outweigh the benefits of horizontal scaling for many use cases.
Application servers typically scale horizontally well. Stateless web applications can distribute across multiple servers easily. Load balancers can route traffic based on server capacity and health.
Caching layers might use hybrid approaches. In-memory caches benefit from vertical scaling (more RAM per server), but distributed caching provides better fault tolerance and capacity scaling.
Multi-Tier E-commerce Scaling Strategy: A major e-commerce platform implemented a hybrid scaling approach across their technology stack. Their PostgreSQL database cluster uses vertical scaling with high-memory instances (up to 768GB RAM) for complex product catalog queries and transaction processing. The web application tier scales horizontally with auto-scaling groups that can expand from 10 to 100 instances during Black Friday traffic spikes. Their Redis caching layer combines both approaches: individual cache nodes are vertically scaled for memory capacity, while the cache cluster scales out across multiple availability zones for redundancy. This hybrid approach reduced database query times by 60% while handling 10x traffic increases during peak shopping events.
Dynamic Scaling Strategies
Advanced implementations can dynamically choose between scaling approaches based on real-time conditions. Dynamic scaling is the future:
Smart systems can choose scaling strategies automatically based on workload patterns. Machine learning algorithms can analyze workload patterns and automatically select the most appropriate scaling strategy.
CPU-intensive tasks might trigger vertical scaling, while I/O-bound workloads get distributed horizontally. Time-based scaling patterns help optimize costs. Predictable daily or seasonal traffic patterns can trigger pre-emptive scaling. If you know traffic spikes happen every Monday morning, pre-scale before users even show up. Batch processing jobs might benefit from temporary vertical scaling during processing windows.
Workload-specific scaling responds to the type of requests being processed. CPU-intensive tasks might trigger vertical scaling, while I/O-intensive workloads might benefit from horizontal distribution.
Cost optimization algorithms can balance performance requirements with budget constraints. During low-priority processing periods, the system might choose more cost-effective scaling approaches even if they provide slightly lower performance.

Kubernetes implements horizontal pod autoscaling as a control loop that runs intermittently. The interval is set by the –horizontal-pod-autoscaler-sync-period parameter to the kube-controller-manager, with a default interval of 15 seconds.
Runpod: Simplifying AI Infrastructure Scaling
The AI Infrastructure Challenge
GPU workloads throw traditional scaling wisdom out the window. GPUs are expensive, power-hungry, and often sit idle between training runs. Traditional scaling approaches fall short when dealing with these constraints.
The complexity of scaling decisions becomes particularly challenging in AI and machine learning workloads, where GPU resources are expensive and demand can be highly variable. Traditional scaling approaches often fall short when dealing with the unique requirements of AI infrastructure.
Platforms like Runpod solve this by providing "bursty compute" - you get access to powerful GPU resources when you need them without paying for idle time. Runpod eliminates the need to choose between expensive upfront investments in high-end GPU hardware (scale up) or the complexity of managing distributed GPU clusters (scale out). Their platform provides "bursty compute" capabilities that allow you to scale resources dynamically based on actual demand, avoiding the common problem of paying for idle GPU resources.
It's like having both vertical scaling (powerful individual GPUs) and horizontal scaling (distributed processing) without the operational headache. The platform's serverless GPU endpoints represent an evolution of scaling paradigms, automatically handling the infrastructure complexity while providing the performance benefits of both approaches. Whether you're training large language models that require massive computational power or deploying inference endpoints that need to handle variable traffic, Runpod's infrastructure scales seamlessly without requiring you to manage the underlying complexity.
This is especially important for AI teams who need to focus on model development, not infrastructure management. When your GPU costs can run thousands per month, dynamic scaling becomes essential for controlling costs. This approach particularly benefits AI teams who can "focus entirely on growth and product development without worrying about GPU infrastructure." By abstracting away the traditional scaling decisions, Runpod enables organizations to leverage both vertical scaling (through access to high-performance GPU instances) and horizontal scaling (through distributed serverless endpoints) without the operational overhead typically associated with these approaches.
Ready to eliminate scaling complexity from your AI infrastructure? Explore Runpod's serverless GPU platform and see how dynamic scaling can accelerate your AI development while optimizing costs.
Final Thoughts
Scaling decisions aren't permanent. You can start with one approach and evolve as your needs change. The most successful teams I've worked with treat scaling as an ongoing process, not a one-time decision.
Scaling decisions shape the foundation of your infrastructure strategy, but they don't have to be permanent or binary choices. The most successful organizations recognize that scaling up and scaling out aren't mutually exclusive approaches - they're complementary strategies that can be applied strategically across different parts of your system.
Don Don't let perfect be the enemy of good. Sometimes the "wrong" scaling decision that you can implement quickly is better than the "right" decision that takes months to plan and execute.
Your application architecture, business requirements, and team capabilities should drive these decisions more than theoretical performance benchmarks or industry trends. What works for a high-frequency trading platform won't necessarily work for a content management system or machine learning pipeline.
Your users care about performance and reliability, not whether you're using the latest architectural patterns. Focus on solving real problems, not impressing other engineers with your scaling sophistication.
The evolution toward cloud-native and serverless architectures is changing the scaling landscape fundamentally. These platforms abstract away many traditional scaling decisions, allowing you to focus on business logic rather than infrastructure management. However, understanding the underlying principles remains crucial for making informed architectural decisions and optimizing costs.
The landscape is evolving rapidly. Cloud-native and serverless platforms abstract away many traditional scaling decisions. But understanding the fundamentals helps you make better choices and debug problems when things go wrong.
As AI and machine learning workloads become more prevalent, specialized platforms that handle the unique scaling requirements of GPU-intensive applications are becoming essential. The traditional scaling frameworks we've discussed still apply, but the implementation details and cost considerations change significantly when dealing with expensive, specialized hardware.
Most importantly, measure everything. You can't optimize what you don't measure, and you can't prove your scaling decisions worked without data. Good monitoring pays for itself many times over when you're making scaling decisions under pressure.
Don't expect miracles overnight. I've seen teams think they can flip a switch and suddenly handle 10x traffic. Scaling is more like training for a marathon than sprinting - it takes time, planning, and patience to get it right.
Bottom line: Before you buy anything, spend a week actually monitoring what's happening. You might be surprised by what you find, and you'll definitely make better decisions with real data than gut feelings.
Related comparisons
- RTX 5080 vs NVIDIA A30: Best Value for AI Developers?
- RTX 5080 vs NVIDIA A30: An In-Depth Analysis
- RTX 4090 Ada vs A40: Best Affordable GPU for GenAI Workloads
- NVIDIA H200 vs H100: Choosing the Right GPU for Massive LLM Inference
- OpenAI’s GPT-4o vs. Open-Source Models: Cost, Speed, and Control
- Runpod vs Colab vs Kaggle: Best Cloud Jupyter Notebooks?
Author profile: Moe Kaloub


