Deploying a stateful LangGraph agent to production without decoupled infrastructure guarantees three failure modes: concurrent session collisions, unrecoverable mid-workflow failures, and GPU bills inflated by CPU-bound work. The fix is a two-layer architecture: CPU orchestration separate from GPU inference, both backed by a PostgreSQL checkpointer. This guide builds it end to end."
Failure modes typically fall into a pattern. You have a working LangGraph agent in a notebook (tool calls, multi-step reasoning, decent behavior), and you deploy it as a single containerized service. On day one, everything is fine. Within a few weeks, the cracks show: two users share a thread_id namespace and collide; a failed node wipes an entire 40-step workflow that can’t be replayed, and your GPU bill climbs because the container holding your agent state also holds your inference process, so both scale together despite having completely different concurrency profiles.
The Horizontal-Scaling Problem
LangGraph’s stateful workflows span minutes to hours by design. An agent researching a topic, drafting a report, and revising it through several tool-call cycles might run for many minutes across dozens of node executions. Horizontal scaling with in-process state means each container knows about only its own sessions. A request hitting a different replica starts a new session with no thread_id isolation, because there’s no external state store to share context across replicas.
The node-level failure problem is worse. vLLM inference can fail mid-workflow through network blips, OOM errors, or model timeouts. Without a checkpointer, a failed mid-workflow run is gone. The agent has no memory of what it already completed, so it starts over, consuming more tokens, more time, and more user patience.
There’s a second cost problem. A running LangGraph agent spends significant wall-clock time on CPU-bound work (routing logic, tool dispatch, state management). The LLM calls are high-latency but episodic. If your inference layer lives in the same container as your orchestration logic, you’re paying GPU prices for work that doesn’t need a GPU.
The Two-Layer Fix
Separate concerns into two independently scaling compute layers, backed by a shared external state store:
- Orchestration layer: CPU containers running FastAPI plus a LangGraph
StateGraph. Scales horizontally with concurrent agent sessions. - Inference layer: GPU serverless workers running vLLM on Runpod Serverless. Scales with LLM call volume.
Both layers persist StateGraph state to an external PostgreSQL checkpointer rather than holding it in process. PostgreSQL is the shared state backend, not a third scaling tier: it scales with standard database techniques (connection pooling, read replicas, vertical sizing).
Each layer scales independently: orchestration with session volume, inference with LLM call volume.
Architecture Overview
The data flow ties the two compute layers and the state store together:
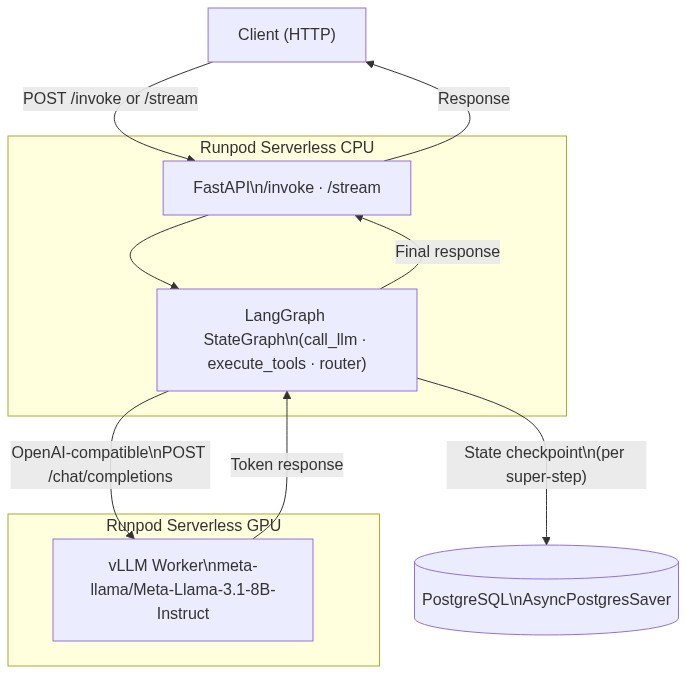
A client sends a POST /invoke with a thread_id and input message. FastAPI passes it to graph.ainvoke(). The StateGraph runs step by step: call_llm sends messages to the Runpod vLLM endpoint, execute_tools dispatches tool calls, and a router conditional edge decides whether to continue, loop, or end. PostgreSQL persists state at each super-step boundary (in a sequential graph, that means after each node completes).
Swapping the model means updating ENDPOINT_ID only. The graph topology, tools, and PostgreSQL schema stay fixed, which is the operational payoff of the decoupled architecture.
1. Standing Up the vLLM Inference Layer
Log into the Runpod console. Navigate to Serverless -> Quick Deploy -> select the Serverless vLLM card.
In the Model field, enter your Hugging Face model ID. For a solid production starting point, use meta-llama/Meta-Llama-3.1-8B-Instruct, which supports a 128K context window. For private models, supply your Hugging Face access token in the token field.
GPU selection matters for production workloads: for fp16 8B-class inference with adequate KV cache headroom, 24GB VRAM or more is a practical starting point. The L40S (48GB) is the cost-efficient default for 8B-class models, handling KV cache allocation comfortably with MAX_MODEL_LEN set to 32K. Use the A100 (80GB) or H100 (80GB) for throughput-sensitive workloads or 70B-class models. Configure active workers (always-warm instances) and max workers to match peak concurrency expectations.
Click Advanced to configure the key engine arguments:
Set MAX_MODEL_LEN explicitly. Leave it at the model’s default (128K for Llama 3.1) and vLLM will pre-allocate KV cache for the full context on initialization, hitting CUDA OOM on the L40S before the first request completes. Set it to the maximum context your agent workflows actually need. For many multi-turn agent sessions, 16K to 32K is a practical starting range.
If you encounter OOM errors after deployment, reduce GPU_MEMORY_UTILIZATION from 0.90 to 0.85. If you have VRAM headroom, raise it toward 0.95 to increase KV cache capacity and throughput.
If your agent uses tool calling, enable it on the vLLM endpoint too. Set ENABLE_AUTO_TOOL_CHOICE=true and TOOL_CALL_PARSER=llama3_json (the parser that matches Llama 3.1’s tool-call format) in the endpoint environment variables. Without these, the server never emits structured tool calls, so the agent’s router never branches to a tool. Match the parser to the model family: llama3_json for Llama 3.x, hermes for Qwen, mistral for Mistral.
After deployment, copy the Endpoint ID from the Serverless dashboard. Use the built-in request testing interface to verify the endpoint is live before wiring it to your agent:
export RUNPOD_API_KEY=“your_runpod_api_key”
export ENDPOINT_ID=“your_endpoint_id”2. Wiring LangGraph’s LLM Client to the Runpod Endpoint
Wiring LangGraph to the Runpod endpoint is one code change. Runpod’s vLLM worker exposes an OpenAI-compatible /chat/completions endpoint. You swap base_url and api_key, bind your tools, and nothing else in your agent changes.
import os
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
# Validate required env vars at startup
ENDPOINT_ID = os.environ.get("ENDPOINT_ID")
RUNPOD_API_KEY = os.environ.get("RUNPOD_API_KEY")
if not ENDPOINT_ID or not RUNPOD_API_KEY:
raise RuntimeError(
"ENDPOINT_ID and RUNPOD_API_KEY must be set as environment variables. "
"Set them in the Runpod Serverless console under Environment Variables."
)
# Replace this stub with your actual tool implementation.
@tool
async def web_search(query: str) -> str:
"""Search the web for information."""
Raise NotImplementedError(“Replace with your actual web search implementation”)
# implement or import your search function
tools = [web_search]
tool_registry = {t.name: t for t in tools}
llm = ChatOpenAI(
model="meta-llama/Meta-Llama-3.1-8B-Instruct",
api_key=RUNPOD_API_KEY,
base_url=f"https://api.runpod.ai/v2/{ENDPOINT_ID}/openai/v1",
# Temperature=0.0 is intentional: non-zero temperature with tool calling can cause the model to
# hallucinate tool names not in your registry
temperature=0.0,
).bind_tools(tools)
The .bind_tools(tools) call is what makes tool calling work on the client side. Without it, the model never emits tool_calls, so the router below always routes straight to the end. The server side matters just as much: tool calling only works if the vLLM endpoint runs with auto tool choice and a matching parser (the ENABLE_AUTO_TOOL_CHOICE and TOOL_CALL_PARSER variables set in Section 1). Message formatting and token streaming need no such flags and work as-is.
To swap models (say, upgrading from Llama 3.1 8B to Llama 3.3 70B), deploy a new Runpod Serverless endpoint, update ENDPOINT_ID, and redeploy the orchestration container. The StateGraph, tools, and checkpointer configuration stay untouched. Match TOOL_CALL_PARSER to the new model family when you switch.
3. Building the StateGraph with Persistent Checkpointing
Start with an explicit state schema; vague schemas make state transitions harder to reason about and debug.
from typing import TypedDict, Annotated
from langgraph.graph.message import add_messages
class AgentState(TypedDict):
messages: Annotated[list, add_messages]
tool_calls_pending: list[dict]
session_id: str
Step_count: int
add_messages is a LangGraph reducer that appends to the message list rather than replacing it, which is essential for multi-turn conversations where earlier messa
ges need to stay in context.
Next come the three node functions. They reuse the tools and tool_registry defined in Section 2:
from langchain_core.messages import ToolMessage, AIMessage
from langgraph.types import Send
from langgraph.graph import END
# Create hard ceiling on node executions per session
# Prevents infinite loops
# Tune base on your expected workflow depth
MAX_STEPS = 25
async def call_llm(state: AgentState) -> dict:
"""Send messages to the Runpod vLLM endpoint."""
response = await llm.ainvoke(state["messages"])
tool_calls = []
if hasattr(response, "tool_calls") and response.tool_calls:
# Use .get() on each field. LangChain has changed tool call object schema across minor versions. Direct key access breaks silently.
tool_calls = [
{"id": tc["id"], "name": tc["name"], "args": tc["args"]}
for tc in response.tool_calls
# Drop any tool calls with missing required fields
If tc.get(“id”) and tc.get(“name”)
]
return {
"messages": [response],
"tool_calls_pending": tool_calls,
“Step_count”: state.get(“step_count”, 0) +1,
}
async def execute_tools(state: AgentState) -> dict:
"""Execute a single tool call (dispatched via Send from router)."""
# Each Send invocation passes a state slice with exactly one tool call.
tool_call = state["tool_calls_pending"][0]
tool_name = tool_call[“name”]
tool_fn = tool_registry.get(tool_name)
If tool_fn is None:
# The model hallucinated a tool name not in the registry.
# Return a ToolMessage with an error string rather than raising KeyError,
# which would crash the entire workflow and lose the checkpoint.
result_content = (
f"Error: tool '{tool_name}' does not exist. "
f"Available tools: {list(tool_registry.keys())}"
)
else:
try:
raw_result = await tool_fn.ainvoke(tool_call["args"])
# str() coercion is intentional for simple string-output tools.
# If your tools return structured dicts or lists that downstream
# nodes need to parse, serialize to JSON here instead:
# result_content = json.dumps(raw_result)
result_content = str(raw_result)
except Exception as e:
# Surface tool execution errors as ToolMessages so the LLM can
# handle them gracefully rather than crashing the workflow.
result_content = f"Error executing tool '{tool_name}': {e}"
# Return only messages. tool_calls_pending has no reducer — parallel
# Send branches must not write it in the same super-step.
return {
"messages": [
ToolMessage(
content=result_content,
tool_call_id=tool_call["id"],
)
],
}
def router(state: AgentState):
"""Route to parallel tool execution or END.
Must remain synchronous as LangGraph conditional edges do not support async.
"""
# Hard ceiling: if the agent hasn't reached END after MAX_STEPS executions,
# force termination. Without this, a model that loops on tool calls runs
# indefinitely until it hits a timeout or exhausts your token budget.
if state.get("step_count", 0) >= MAX_STEPS:
return END
if not state["tool_calls_pending"]:
return END
# Send API: fan out one branch per tool call, execute in parallel.
# Each Send passes a state slice with exactly one item in tool_calls_pending.
# execute_tools always reads index [0] — this is the contract.
return [
Send("execute_tools", {**state, "tool_calls_pending": [tc]})
for tc in state["tool_calls_pending"]
]
The router function’s use of Send enables parallel tool dispatch. When the LLM returns three tool calls simultaneously, router returns three Send objects. LangGraph fans them out as concurrent graph branches, collects their ToolMessage outputs (merged via the add_messages reducer), and sends the merged state back to call_llm for the next iteration. Sequential dispatch would require three round-trips before the LLM sees any results. The Send pattern collapses that to one.
One production detail makes or breaks that parallelism. A super-step is one complete round of node execution: when router fans out three parallel Send branches, all three run inside the same super-step. Within a parallel super-step, branches may only write state channels that have a reducer. messages has one (add_messages), so concurrent ToolMessage appends merge cleanly. tool_calls_pending does not, which is why execute_tools returns only messages and lets call_llm reset the pending list on the next super-step. Writing a reducer-less channel from multiple parallel branches in the same super-step raises InvalidUpdateError, and it surfaces exactly when more than one tool call fires at once, the case this design is built for.
Install the checkpoint dependencies, then wire the saver into the graph. You will need a PostgreSQL instance reachable from Runpod’s network; Section 4 covers provisioning options.
pip install langgraph-checkpoint-postgres "psycopg[binary,pool]"Import os
from psycopg.rows import dict_row
from psycopg_pool import AsyncConnectionPool
from langgraph.checkpoint.postgres.aio import AsyncPostgresSaver
from langgraph.graph import StateGraph, END
async def build_graph(db_url: str):
# Pull pool size from env and tune for your expected concurrency
# Default of 10 is conservative; raise it if you see connection wait times.
pool_size = int(os.environ.get("DB_POOL_SIZE", "10"))
# AsyncPostgresSaver requires psycopg (psycopg3), not asyncpg.
# These kwargs are not optional:
# autocommit — setup() issues DDL that requires it
# dict_row — the saver expects dict-style row access
# prepare_threshold=0 — prevents prepared-statement errors behind
# PgBouncer / Supabase transaction poolers
pool = AsyncConnectionPool(
conninfo=db_url,
max_size=pool_size,
open=False,
kwargs={"autocommit": True, "prepare_threshold": 0, "row_factory": dict_row},
)
await pool.open()
checkpointer = AsyncPostgresSaver(pool)
# Creates checkpoint tables (idempotent, safe to call on every startup)
await checkpointer.setup()
builder = StateGraph(AgentState)
builder.add_node("call_llm", call_llm)
builder.add_node("execute_tools", execute_tools)
builder.set_entry_point("call_llm")
# router is synchronous by design - LangGraph conditional edges do not support asynch functions
builder.add_conditional_edges("call_llm", router)
builder.add_edge("execute_tools", "call_llm")
return builder.compile(checkpointer=checkpointer)
Those connection kwargs are not optional. setup() issues table-creation DDL that needs autocommit, the saver expects dict_row, and prepare_threshold=0 keeps checkpoint queries working behind the transaction poolers that managed Postgres providers (Supabase, PgBouncer) put in front of the database. For a simpler single-process setup without a shared pool, AsyncPostgresSaver.from_conn_string(db_url) applies the same settings internally.
Invoke the compiled graph with a per-session thread_id in the run config:
config = {"configurable": {"thread_id": "user-session-abc123"}}
result = await graph.ainvoke(
{"messages": [user_message], "session_id": "abc123", “step_count”: 0, },
config,
)
LangGraph stores each session’s checkpoints keyed by thread_id, so concurrent invocations with different thread_id values don’t interfere with each other. A session spanning 50 node executions over 30 minutes keeps its full state intact across all of them, regardless of which CPU container handles each request. With the graph wired and checkpointing confirmed, the next step is packaging the orchestration layer into a deployable container.
4. Containerizing and Deploying the Orchestration Layer
The minimal Dockerfile:
FROM python:3.12-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8000
# Single worker is correct here — Runpod handles horizontal scaling at the
# Serverless worker level, not within the container. uvloop improves async
# throughput without adding concurrency complexity.
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000", "--loop", "uvloop"]
requirements.txt, pinned to tested ranges (LangGraph has shipped import-path and API changes across minor versions, so cap the upper bound):
fastapi>=0.111.0
uvicorn[standard]>=0.29.0
langgraph>=1.0.0,<2.0.0
langgraph-checkpoint-postgres>=2.0.0,<3.0.0
langchain-openai>=0.1.0
# Pin langchain-core directly so minor version changes don’t break tool call schema.
langchain-core>=0.2.0,<0.3.0
psycopg[binary]>=3.1.0
psycopg-pool>=3.1.0
The FastAPI service (main.py):
import os
Import json
from contextlib import asynccontextmanager
from fastapi import FastAPI
from fastapi.responses import StreamingResponse, JSONResponse
from pydantic import BaseModel
from langchain_core.messages import HumanMessage, AI message
graph = None
@asynccontextmanager
async def lifespan(app: FastAPI):
global graph
graph = await build_graph(os.environ["DATABASE_URL"])
yield
app = FastAPI(lifespan=lifespan)
class InvokeRequest(BaseModel):
thread_id: str
message: str
@app.post("/invoke")
async def invoke(request: InvokeRequest):
config = {"configurable": {"thread_id": request.thread_id}}
result = await graph.ainvoke(
{
"messages": [HumanMessage(content=request.message)],
"session_id": request.thread_id,
“step_count”: 0,
},
config,
)
except Exception as e:
# Return a structured error rather than a raw 500.
# The checkpoint state is preserved — the client can retry.
return JSONResponse(
status_code=500,
content={"error": str(e), "thread_id": request.thread_id},
)
# The final message should be an AIMessage. If it's a ToolMessage,
# the graph exited mid-cycle (e.g. after hitting MAX_STEPS).
# Surface this clearly rather than returning tool output as the response.
final_message = result["messages"][-1]
if not isinstance(final_message, AIMessage):
return JSONResponse(
status_code=500,
content={
"error": "Graph exited without a final AI response. "
"This may indicate the MAX_STEPS ceiling was hit.",
"thread_id": request.thread_id,
},
)
return {"response": final_message.content, , "thread_id": request.thread_id}
@app.post("/stream")
async def stream(request: InvokeRequest):
config = {"configurable": {"thread_id": request.thread_id}}
async def generate():
# stream_mode="messages" yields (message_chunk, metadata) tuples;
# the first element is a single message, not a list.
async for msg, metadata in graph.astream(
{
"messages": [HumanMessage(content=request.message)],
"session_id": request.thread_id,
“step_count”: 0,
},
config,
stream_mode="messages",
):
if metadata.get("langgraph_node") == "call_llm":
if hasattr(msg, "content") and msg.content:
# SSE format: browsers using EventSource expect "data: ...\n\n" framing. text/plain works # for curl and simple HTTP clients but not EventSource.
yield f"data: {json.dumps({'error': str(e)})}\n\n"
return StreamingResponse(generate(), media_type="text/event-stream")
Build and push the image:
# Specify linux/amd64 (required for Runpod's infrastructure)
docker build --platform linux/amd64 -t yourdockerhub/langgraph-agent:1.0.0 .
docker push yourdockerhub/langgraph-agent:1.0.0
Use a version tag instead of latest. Runpod caches layers aggressively, and latest will serve stale images after updates.
Before deploying the orchestration layer, provision an external PostgreSQL instance reachable from Runpod’s network. A managed database (Neon, Supabase, Railway, or RDS) works and is reachable over the public internet; so does a self-hosted Postgres on a VPS or a Runpod Pod running PostgreSQL. Because the connection runs over the public internet, require TLS by appending ?sslmode=require to the connection string. Store the full string as DATABASE_URL. The checkpointer.setup() call in build_graph() creates the checkpoint tables on first startup, so you don’t run migrations manually.
To deploy to Runpod Serverless CPU:
- In the Runpod console, navigate to Serverless -> New Endpoint.
- Click Import from Docker Registry and enter your image URL.
- Under Worker Type, select CPU.
- Under Environment Variables, add:
RUNPOD_API_KEY(used to authenticate calls to the vLLM endpoint)ENDPOINT_ID(the vLLM endpoint ID from Section 1)DATABASE_URL(your PostgreSQL connection string, e.g.,postgresql://user:pass@host:5432/agents?sslmode=require)
- Configure container concurrency based on your expected concurrent agent sessions per worker.
- Click Deploy.
No Network Volume is required for this architecture. Because state is externalized to PostgreSQL, the container filesystem stays ephemeral by design. Runpod autoscales the orchestration layer horizontally using Flex workers. When incoming request concurrency saturates the active workers, new containers spin up automatically.
5. Monitoring, Debugging, and Replay
A spike in GPU queue depth and a spike in CPU error rate mean different things and need different fixes. Each Runpod Serverless endpoint surfaces its own metrics independently so you can keep track of them separately.On the CPU orchestration endpoint, watch request logs, worker state transitions, and error output. GPU-side, the vLLM endpoint surfaces execution-time metrics, cold-start tracking, and queue-based scaling signals. Watch them separately, because a spike in GPU queue depth signals that the inference layer needs more max workers, while a spike in CPU error rate points to a bug in the orchestration layer.
Because the checkpointer writes state at each super-step boundary, a mid-workflow failure loses at most the last super-step’s work; a failure mid-parallel-dispatch rolls back to the state before any of those tools ran. To inspect and resume:
# Retrieve the last successful state for this session
config = {"configurable": {"thread_id": "user-session-abc123"}}
state_snapshot = await graph.aget_state(config)
print(state_snapshot.values) # Full state dict at last checkpoint
print(state_snapshot.next) # Nodes scheduled to execute next
print(state_snapshot.created_at) # Timestamp of last successful checkpoint
# Resume from the checkpoint: LangGraph skips nodes already saved
# and re-runs from the last checkpoint boundary.
result = await graph.ainvoke(None, config)
Passing None as the input tells LangGraph to resume from the last checkpoint rather than starting a new run. The agent picks up from the last saved super-step. For long-running workflows that call many tools, checkpoint resumption is the difference between a recoverable failure and a full restart that wastes the tokens and minutes already spent.
The architecture and Runpod’s per-second pricing change the cost math. CPU containers bill per second of compute consumed;GPU workers bill per second of GPU compute consumed, which is only when inference is actually running. . Because the two layers scale independently, you’re not paying GPU rates for routing logic, tool dispatch, or state management. Both layers scale to zero when there’s no traffic. On equivalent workloads, teams moving from traditional cloud providers to RunPod Serverless typically save 80-90% on compute costs.
Coframe scaled from zero to hundreds of concurrent GPU workers in under 250 milliseconds via FlashBoot when traffic spiked on launch day - no infrastructure team, no pre-provisioning.
Frequently Asked Questions
What is a LangGraph checkpointer and why does it matter for production deployments?
It persists StateGraph state to an external store (here, PostgreSQL) at each super-step boundary, described in Section 3. A failed super-step loses at most that step’s work, not the entire workflow. Without a checkpointer, any mid-workflow failure restarts from the beginning, discarding the tokens and time already spent.
How does thread_id isolation work across multiple Runpod CPU containers?
To track state, LangGraph keys each session’s checkpoints by thread_id in PostgreSQL, enabling any CPU container to serve any session without collision, and ensuring concurrent sessions with different thread_id values never interfere with each other.
When should I use the L40S versus A100 or H100 for vLLM inference on Runpod?
Use the L40S (48GB) for 8B-class models like Llama 3.1 8B at MAX_MODEL_LEN of 32K or below. Step up to the A100 or H100 (80GB) for 70B-class models, very long context windows, or throughput-heavy batching where per-request cost matters less.
Why does MAX_MODEL_LEN need to be set explicitly instead of using the model default?
vLLM pre-allocates KV cache for the full MAX_MODEL_LEN at startup, so leaving Llama 3.1 at its 128K default exhausts an L40S’s VRAM and triggers CUDA OOM before the first request. Set it to the context your workflows actually use, typically 16K to 32K (see Section 1).
How does the Send API enable parallel tool execution in LangGraph?
The router returns one Send object per tool call, and LangGraph runs those branches concurrently within a single super-step, merging their ToolMessage outputs through the add_messages reducer (see Section 3). Without Send, the calls run one at a time, a full round-trip each.
What happens to in-flight agent sessions when the CPU orchestration container scales down?
Nothing is lost. Session state lives in PostgreSQL, not container memory, so when a new container picks up the next request for that thread_id, it reads the last checkpoint and resumes from the last saved super-step.
Does this architecture require Kubernetes or infrastructure orchestration tooling?
No. Runpod Serverless handles container scheduling, autoscaling, and worker lifecycle without Kubernetes, Helm, or YAML. The orchestration layer ships from a Docker registry, the inference layer via Quick Deploy, and the only infrastructure you manage is the PostgreSQL database.
Conclusion
Separate what scales differently, persist state externally, and keep inference and orchestration on their own cost axes. That’s the whole architecture.
The vLLM layer goes live in minutes via Quick Deploy. The orchestration layer ships straight from a Docker registry with no YAML to write. The result is a production stateful-agent stack with no Kubernetes, no Helm, and no minimum spend - billed only for the compute each layer actually uses. Start with the vLLM endpoint in Section 1, point your agent at it with RUNPOD_API_KEY and ENDPOINT_ID, and let PostgreSQL carry the state.


