.jpeg)
Deploy When Available is now GA
Queue for any GPU spec, even one that's fully rented out, and we'll deploy it the moment capacity opens up. No more refreshing the console or running a sniping tool.
All
Blog
Learn how to deploy Meta's Llama 3.1 8B Instruct model using the vLLM inference engine on Runpod Serverless for blazing-fast performance and scalable AI.


In this blog, you'll learn:
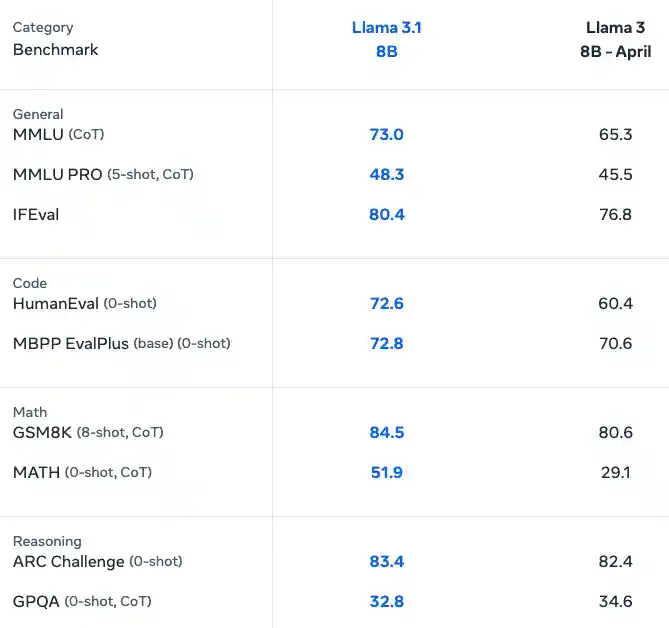
Meta Llama 3.1 is the latest iteration of Meta's powerful open-source language model. It offers improved performance and capabilities compared to its predecessors. While not as large as its 405B counterpart, the 8B instruct version provides a balance of capability and efficiency that's ideal for many use cases. Compared to their predecessors, the Meta Llama 3.1 models perform exceptionally well in benchmark tests:
To run our Meta Llama 3.1 model, we'll leverage vLLM, an advanced inference engine designed to enhance the performance of large language models dramatically. Here are some of the reasons vLLM is a superior option:
The key to vLLM's impressive performance lies in its innovative memory management technique known as PagedAttention. This algorithm optimizes how the model's attention mechanism interacts with system memory, resulting in significant speed improvements. If you're interested in delving deeper into the inner workings of PagedAttention, check out our detailed blog post dedicated to vLLM.
Now let's dive into how you can start running vLLM in less than a few minutes.
Follow the step-by-step guide below with screenshots to run inference on the Meta Llama 3.1 8b instruct model with vLLM in less than a few minutes. Please note that this guide can apply to any open large language model so feel free to experiment with other Llama or open-source large language models by swapping in their hugging face link and model name in the code.
Pre-requisites:
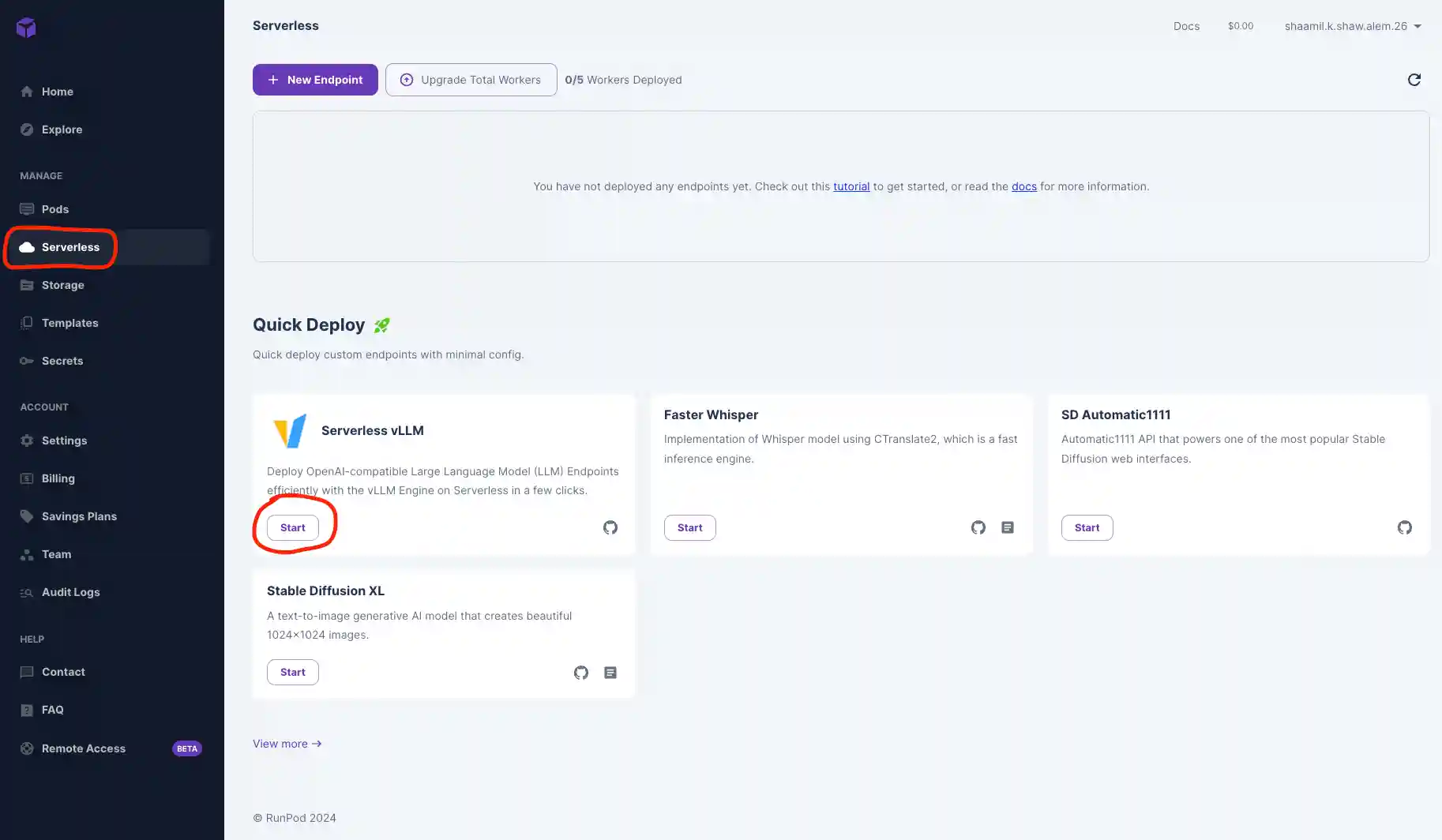
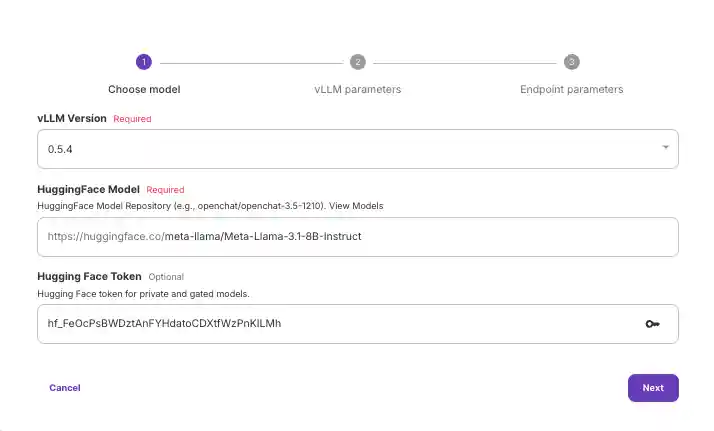
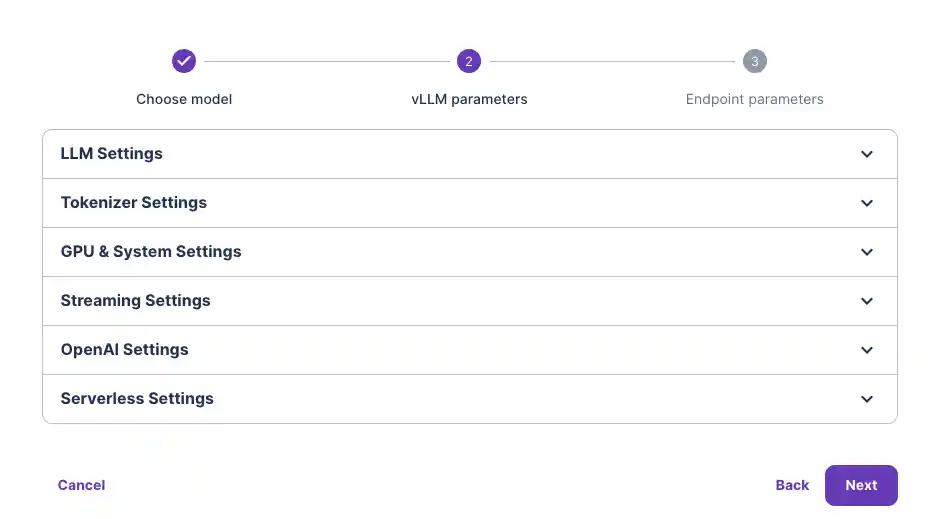
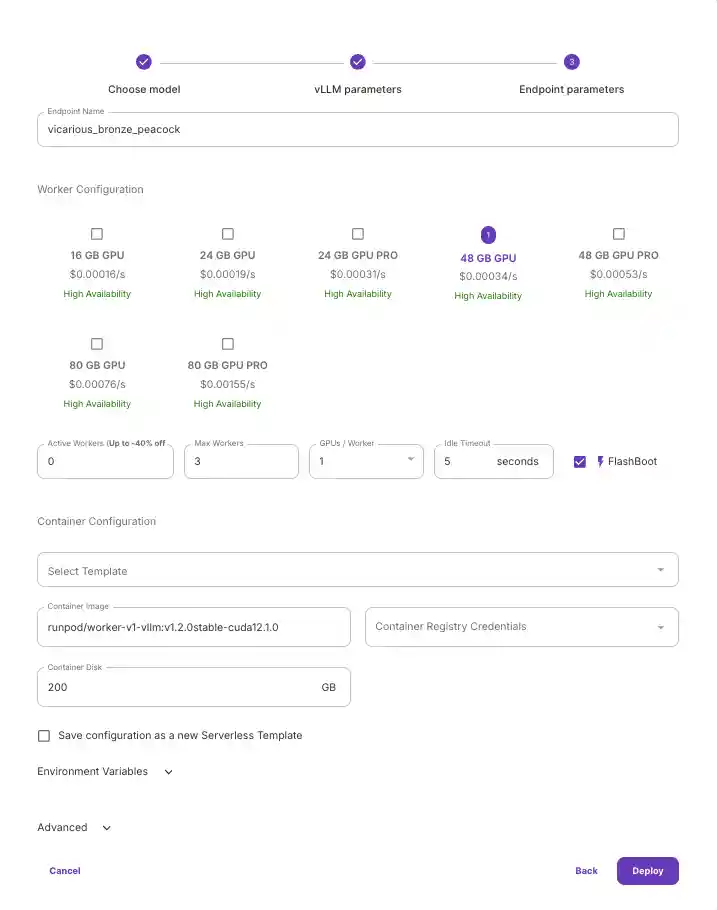
Note: If we were to quantize our model or limit the context window, we could opt for a smaller GPU.
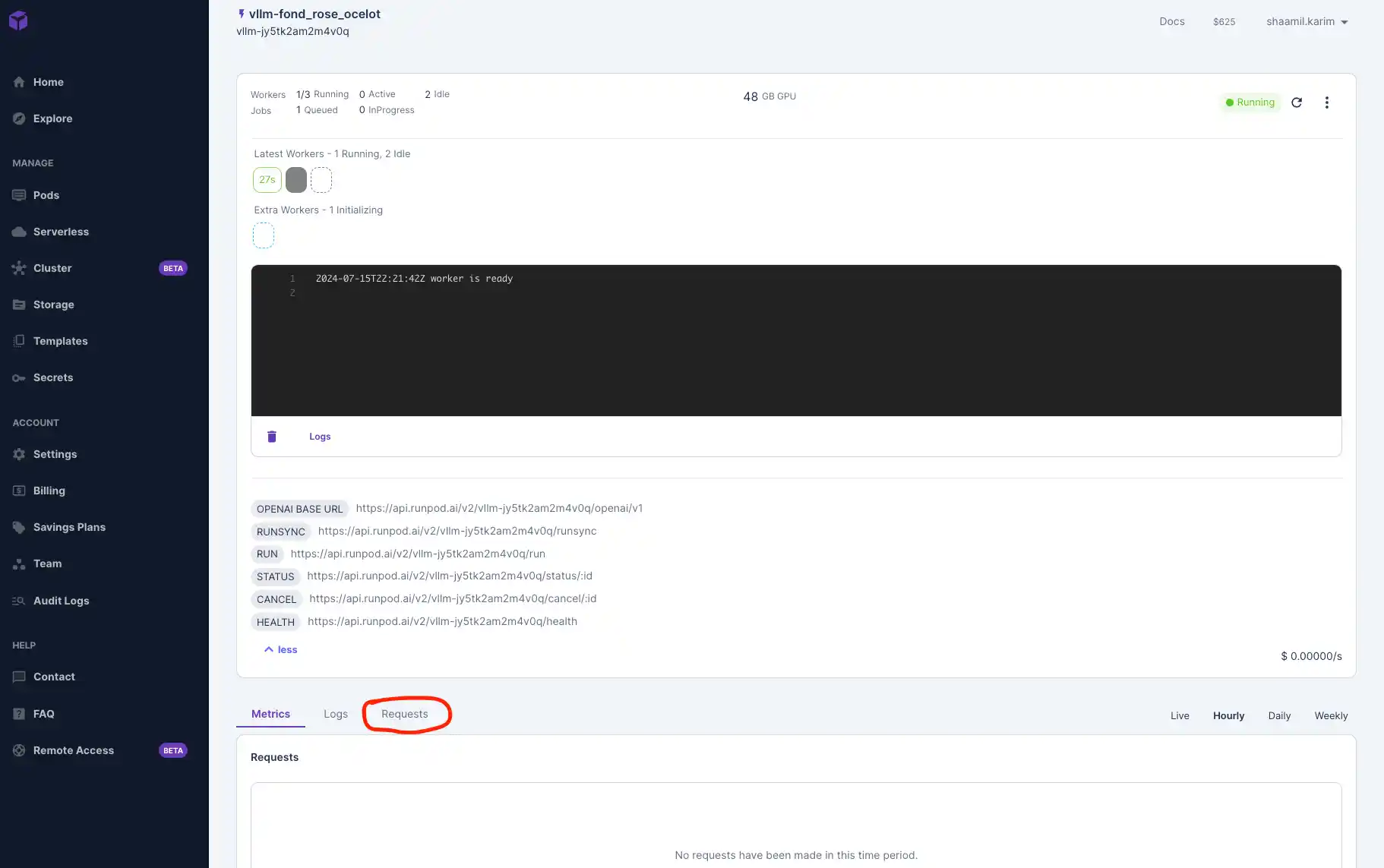
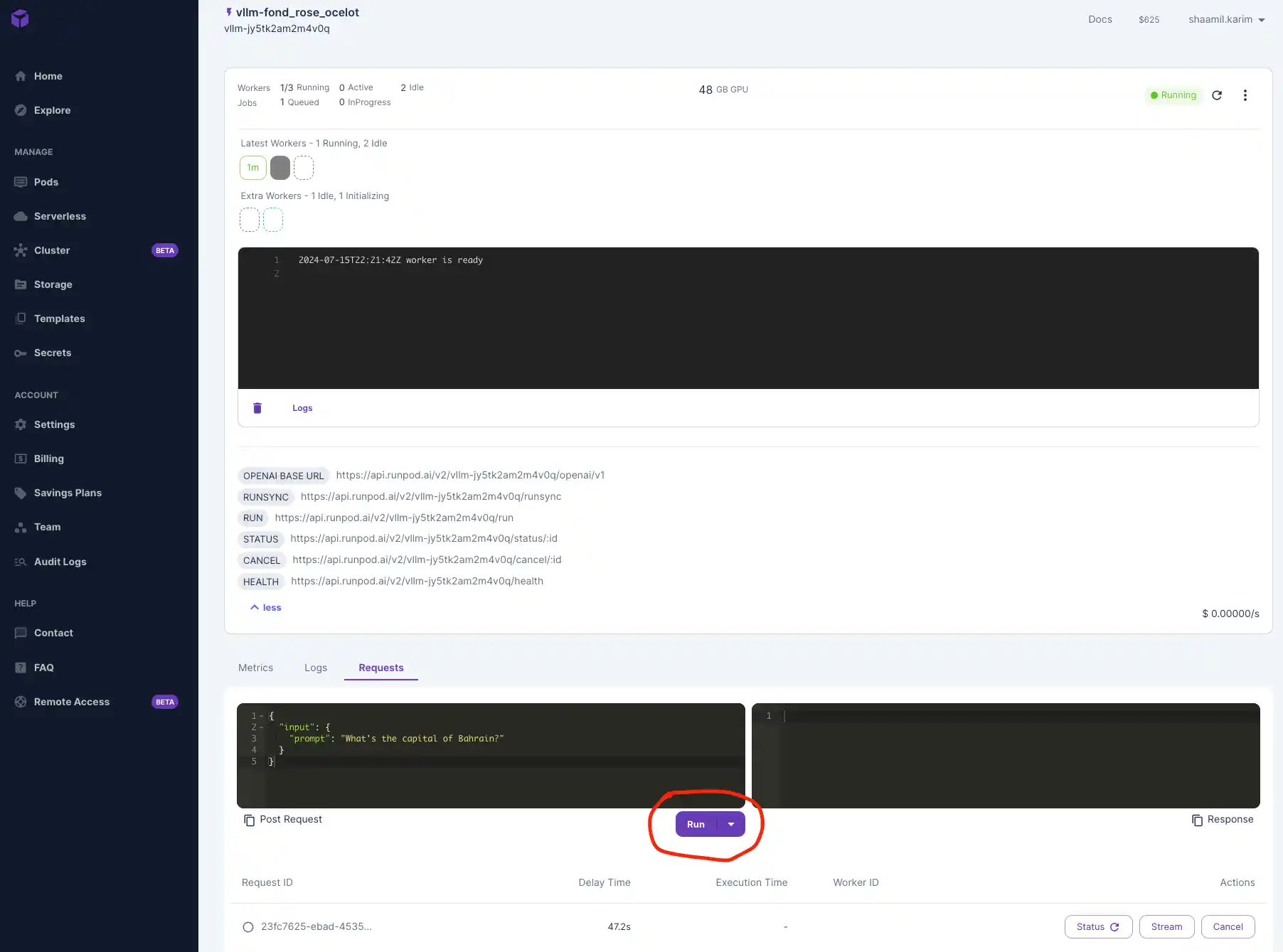
We'll be using Google Colab to test out our model by connecting to the serverless endpoint. Colab which provides a free, cloud-based Jupyter notebook environment that we can leverage to interact with Runpod's serverless infrastructure, allowing us to easily send requests, manage deployments, and analyze results without the need for local setup or resource constraints.
The vLLM Worker is compatible with OpenAI's API, so we will interact with our vLLM Worker as you would with OpenAI's API. We'll also be using While Colab is a popular choice, you're not limited to it – you can also use other development environments like Visual Studio Code (VSCode) with appropriate extensions, or any IDE that can make HTTP requests.
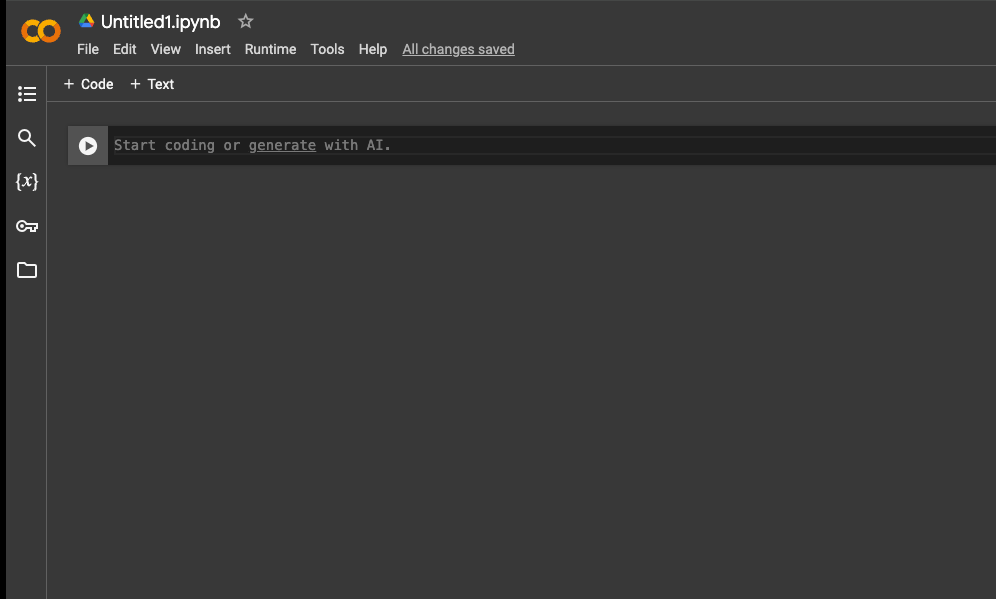
pip install openai
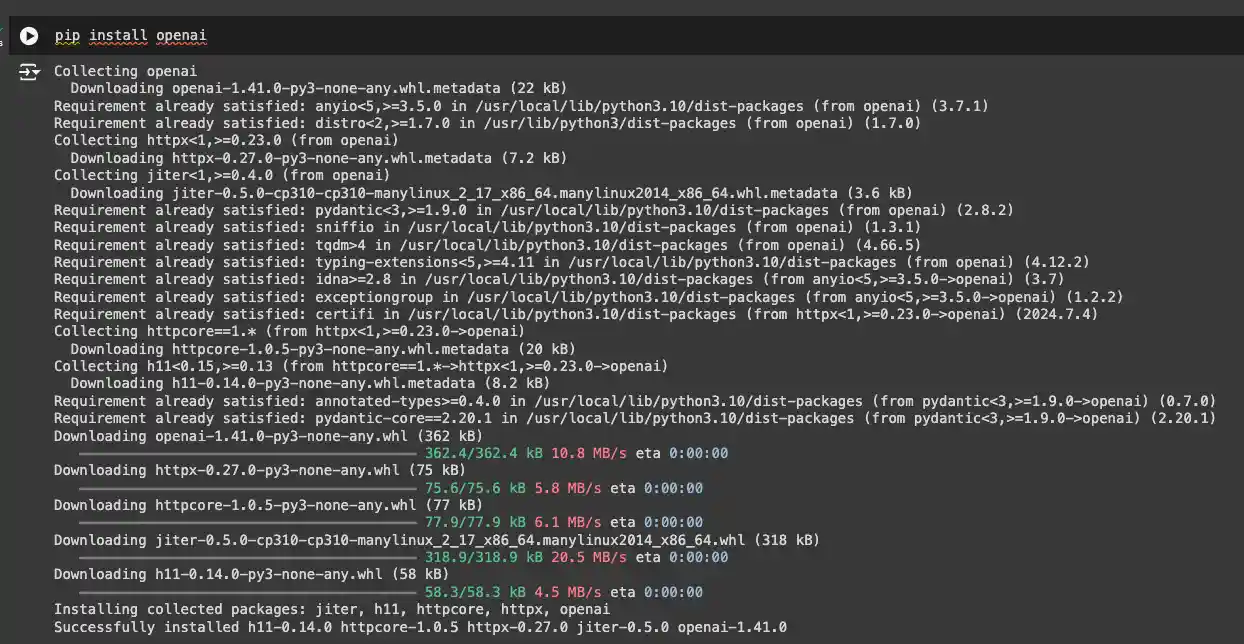
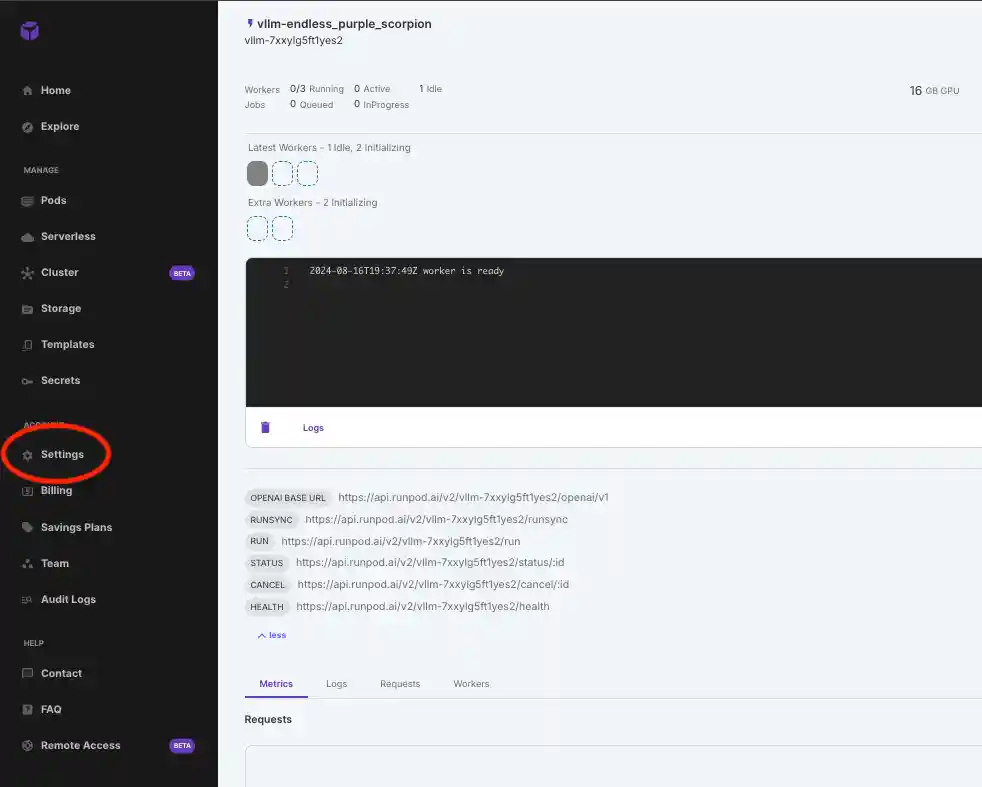
5. Click on API Keys and create your API key. Read permissions should be enough for this use case. Copy your API key and now paste it in the code.
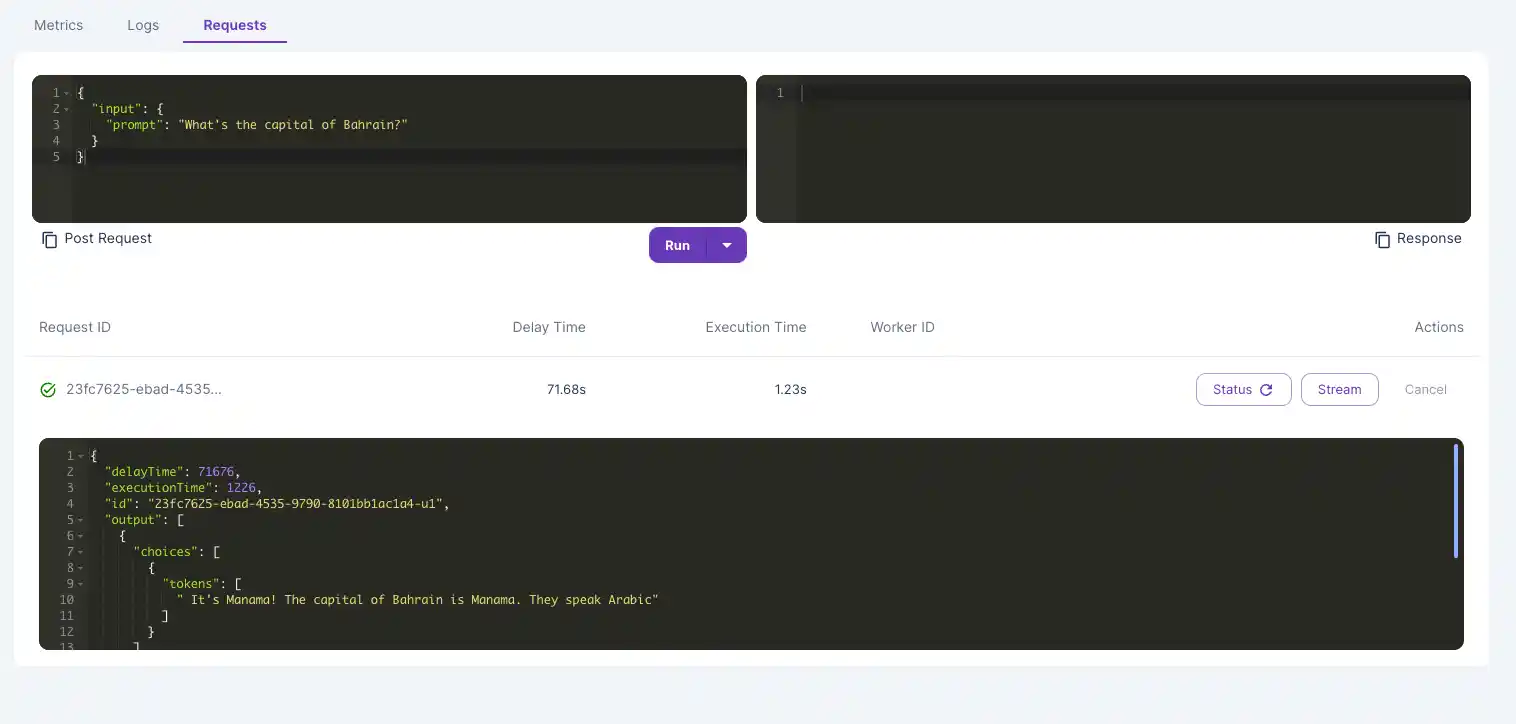
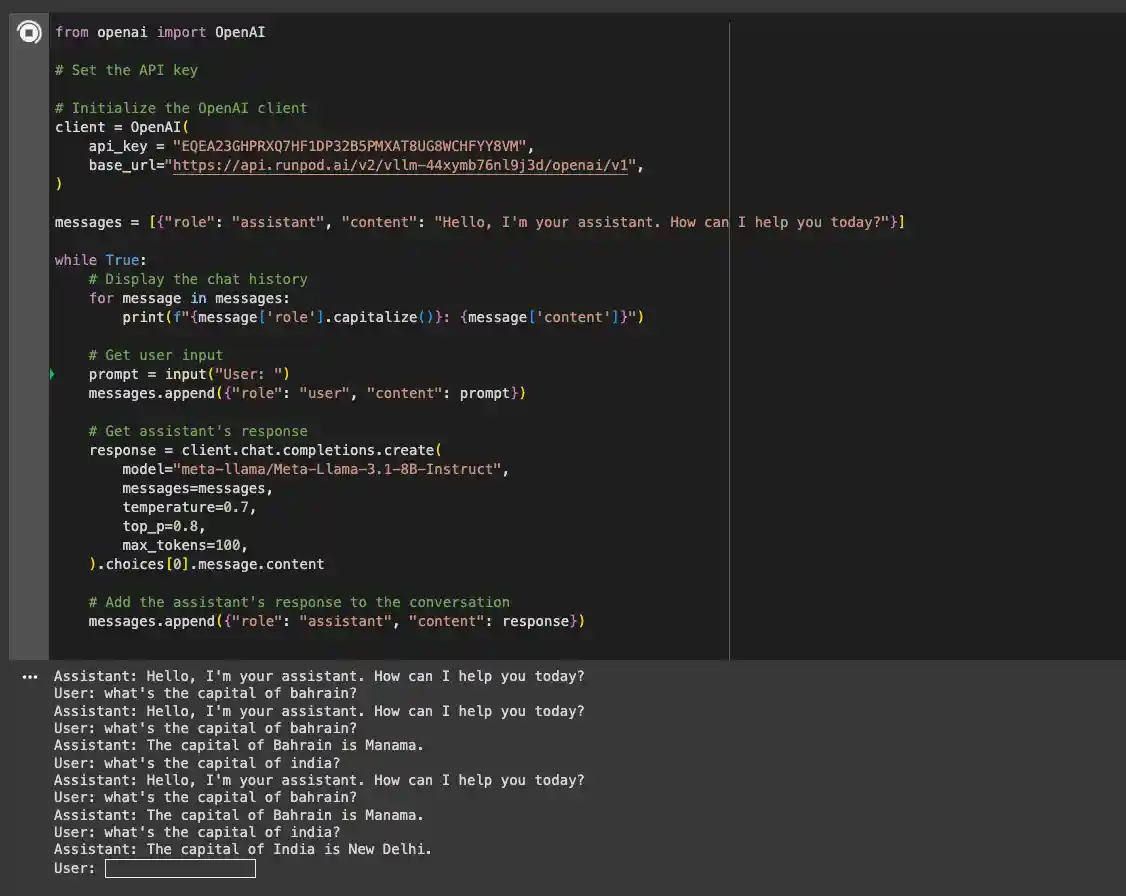
After running the above code, you should be able to chat with your model like below! The code below has its own API key and Base URL which have been deprecated now (obviously). Your first new token will take a few minutes to output but will run smoothly for every other token or request afterwards.
When sending a request to your LLM for the first time, your endpoint needs to download the model and load the weights. If the output status remains "in queue" for more than 5-10 minutes, read below!
Comment below for more help!
In this blog, we've delved into the exciting capabilities of Llama 3.1, with a particular focus on its efficient 8B instruct version. We've explored the benefits of this model, highlighting its balance of performance and efficiency that makes it ideal for a wide range of applications. We've also discussed why vLLM is the perfect companion for running Llama 3.1, offering unparalleled speed and extensive model support.
By combining the power of the Meta Llama 3.1 8B instruct with the efficiency of vLLM on Runpod's serverless infrastructure, you're now equipped to leverage state-of-the-art language modeling capabilities for your projects. This powerful combination offers an excellent balance of performance, cost-effectiveness, and user-friendliness.
Get started now with our quick deploy option!
Deploy vLLM on Runpod Serverless
Author profile: Shaamil Karim
Blog Posts
Queue for any GPU spec, even one that's fully rented out, and we'll deploy it the moment capacity opens up. No more refreshing the console or running a sniping tool.

Explore why faster chips have shifted the bottleneck to AI infrastructure, and what that means for teams running production workloads.
.jpeg)
With MIG, we can partition RTX 6000 Pro cards into isolated 24 GB instances. Here's when it makes sense for your workloads.
