.jpeg)
Deploy When Available is now GA
Queue for any GPU spec, even one that's fully rented out, and we'll deploy it the moment capacity opens up. No more refreshing the console or running a sniping tool.
All
Blog
Deploy any Hugging Face large language model using Runpod's configurable templates. Customize your endpoint with ease and launch scalable LLM deployments.


Runpod introduces Configurable Templates, a powerful feature that allows users to easily deploy and run any large language model.
With this feature, users can provide the Hugging Face model name and customize various template parameters to create tailored endpoints for their specific needs.
Configurable Templates offer several benefits to users:
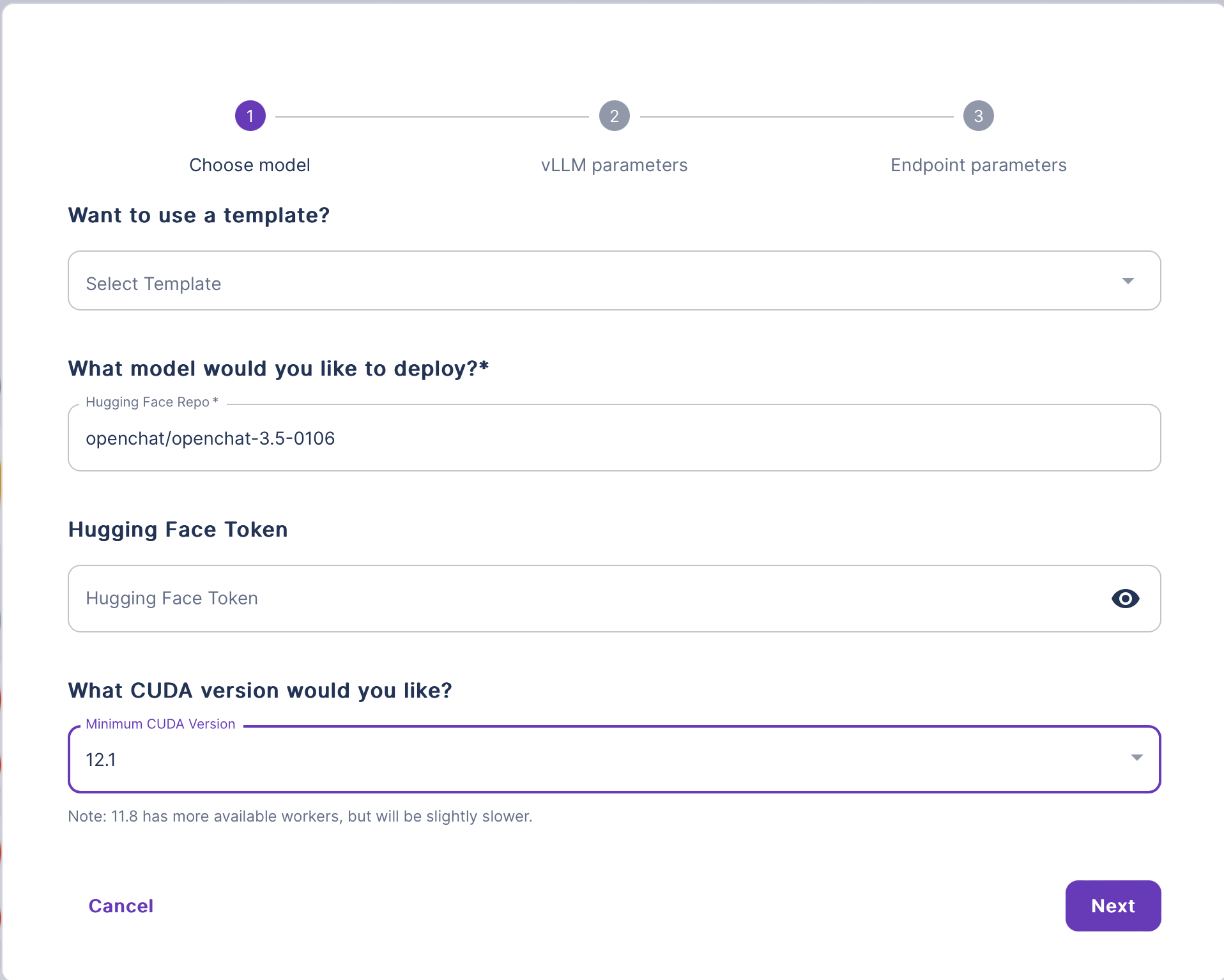
Follow these steps to deploy a large language model using Configurable Templates:
Once the deployment is complete, your LLM will be accessible via an Endpoint. You can interact with your model using the provided API.
💡
Runpod supports any model architecture that can run on vLLM with configurable templates.
By integrating vLLM into the Configurable Templates feature, Runpod simplifies the process of deploying and running large language models. Users can focus on selecting their desired model and customizing the template parameters, while vLLM takes care of the low-level details of model loading, hardware configuration, and execution.
Author profile: Brendan McKeag
Blog Posts
Queue for any GPU spec, even one that's fully rented out, and we'll deploy it the moment capacity opens up. No more refreshing the console or running a sniping tool.

Explore why faster chips have shifted the bottleneck to AI infrastructure, and what that means for teams running production workloads.
.jpeg)
With MIG, we can partition RTX 6000 Pro cards into isolated 24 GB instances. Here's when it makes sense for your workloads.
