
Why companies are choosing nimble cloud platforms over hyperscalers
Iterative AI teams are shifting from hyperscalers to purpose-built AI clouds. Learn how to optimize iteration speed, scale instantly, and cut costs by up to 90%.
All
Blog
DeepSeek V4 is not the "Sputnik moment" R1 was, but it is the cheapest credible alternative to Claude Opus and GPT-5.5 that anyone has shipped thus far.

.avif)
DeepSeek's V4 preview landed on April 24, 2026 with two MoE models: V4-Pro (1.6T total / 49B active) and V4-Flash (284B / 13B active), with both shipping under MIT license with a 1M-token context window, with real-world inference costs that pound for pound undercut every frontier lab by roughly an order of magnitude. Two days in, the practitioner verdict is more interesting than the marketing. This guide walks through what people are actually doing with it, where it falls down, and exactly how to stand it up on Runpod with vLLM or SGLang.
DeepSeek V4 is a Mixture-of-Experts release with a genuinely new attention stack. DeepSeek interleaves Compressed Sparse Attention (CSA) with Heavily Compressed Attention (HCA); the first compresses the sequence 4x and uses a top-k indexer, the second compresses 128x into a dense MQA stream and a 128-token sliding window handles recency. The result: at 1M tokens, V4-Pro uses only 27% of the per-token FLOPs and 10% of the KV cache of V3.2; Flash drops those to 10% and 7%. They also replaced standard residuals with Manifold-Constrained Hyper-Connections, swapped AdamW for the Muon optimizer on most parameters, and quantization-aware-trained the MoE experts down to MXFP4 with FP8 for everything else. That's why Pro is "only" 865 GB on disk and Flash fits in 160 GB, being extremely dense for their parameter counts.
Two other facts shape every deployment decision. The API is drop-in for both OpenAI and Anthropic clients. DeepSeek explicitly publishes ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic so Claude Code can be repointed in one env var; you could simply swap out the URL of your pod if you were to host V4 on Runpod. And both models expose three reasoning modes: Non-think, Think High, and Think Max (the last requires ≥384K context).
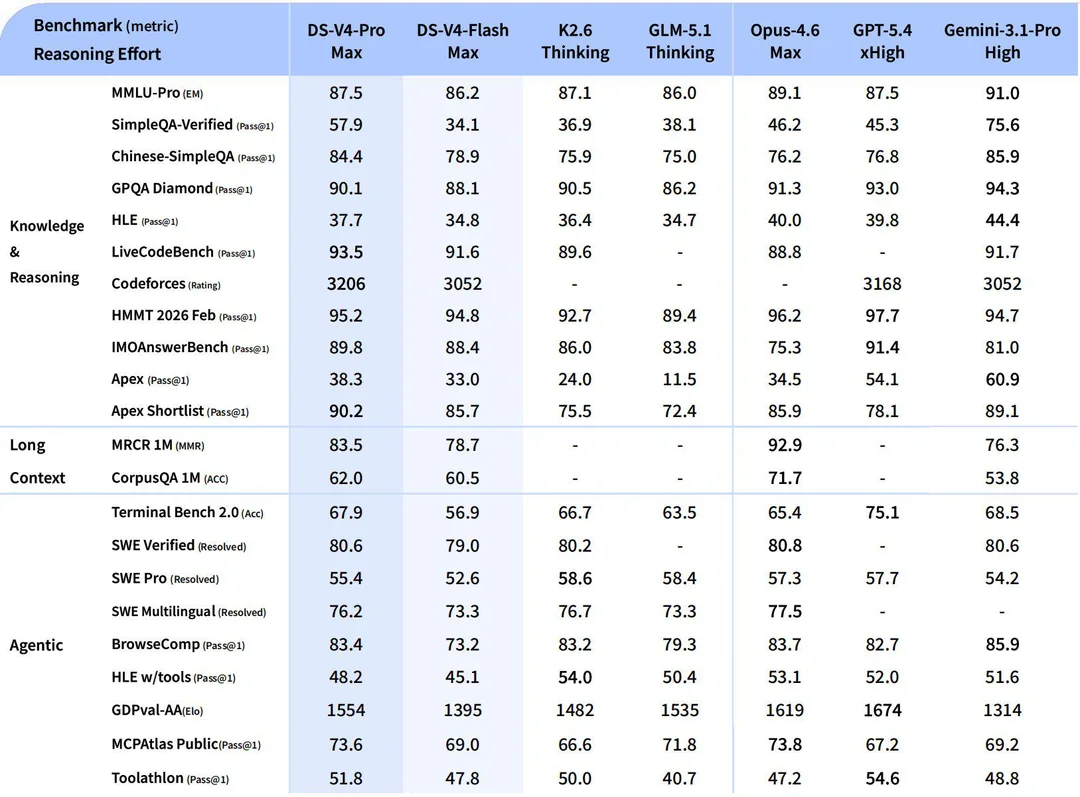
On benchmarks V4-Pro-Max matches Opus 4.6 across the board, beats it on LiveCodeBench (93.5) and Codeforces (3,206, roughly rank 23 among human contestants), and trails GPT-5.4 and Gemini 3.1 Pro on the harder reasoning evals.
The single biggest pattern in launch-week threads is teams keeping the Claude Code (or OpenCode, or OpenClaw) UX they already know and swapping inference to DeepSeek. The full migration is a five-line env block:
We've previously gone into this process on our YouTube channel; this video was released a few months ago, but the process should still hold.
V4-Flash is fast and cheap enough to stand in for Claude Haiku or Gemini Flash-Lite as the default model in tool-calling pipelines, especially when each call drags a long document along. On MRCR (long-context retrieval), V4-Pro topped the open-source field and beat Opus 4.7, though it does drop to 66% accuracy at the full 1M tokens, so don't confuse "supports 1M" with "reliable at 1M." Sweet spot is 128K–512K, where MRCR holds at 82–94%.
This is where V4 quietly looks frontier-ish. V4-Pro hits 3,206 Elo on Codeforces (above Opus 4.6 and Gemini 3.1 Pro), 95.2 on HMMT 2026 February, and 89.8 on IMOAnswerBench. On formal-math benchmarks the numbers are even more striking: V4-Flash-Max scored 81.0 on Putnam-200 Pass@8, an order of magnitude above Seed-2.0-Pro and Gemini-3-Pro, and V4 reached a proof-perfect 120/120 on the Putnam-2025 hybrid setup. If you have a math tutor, theorem-proving harness, or competitive-programming evaluator, this is now the obvious open-weight choice.
The biggest "flaw" (if you want to call it that) is that V4, at least for now, is not a multimodal model; it is text only, and compared to what Gemini, Opus, etc. are able to accomplish that can definitely be inconvenient. However, it's also a problem that can easily be worked around by adding something like a Qwen3-VL model to be called as needed, which is commonly used in a lot of ComfyUI workflows now regardless.
The bigger long-term concern comes from skeptic Mehul Gupta: V4 "stacks techniques to fix scaling limits of earlier techniques ... mHC plus hybrid CSA+HCA plus FP4/FP8 mixed precision all at once, and "Think Max improves scores, but not consistently across tasks." This could be seen as something of a bandaid instead of a robust iteration to correct previous flaws. However, as usual, treat the preview label literally; expect behavior to shift before the final release.
V4-Flash is the practical self-hosting target; its 160 GB FP4+FP8 footprint fits on two H200s with room for KV cache, and decode latency is competitive. V4-Pro is cluster work; the official vLLM recipe wants ~960 GB of mixed-precision footprint, and you'll either fill an 8-GPU H200 or B300 pod or you'll need to step up to a multi-node Cluster.
The engine choice is simple in 2026: pick vLLM or SGLang. Both shipped Day-0 official recipes for V4 with native CSA+HCA support, FP4 MoE backends, MTP speculative decoding, and disaggregated prefill/decode.TGI has no V4 support at preview; Ollama and llama.cpp have unverified community GGUFs only at the moment.
For most teams running V4-Flash, two H200 SXM in a single pod (~$7.18/hr) is the sweet spot — 282 GB of HBM3e fits the model plus comfortable KV for 256K context. If you need full 1M context or high QPS, scale to 8× H200 (~$28.7/hr) and use the disaggregated prefill/decode recipe. For V4-Pro, 8× HGX B300 (~$55.5/hr) is the cleanest single-node deployment — native FP4 execution, full 1M context, no model-len cap. Eight H200s ($28.7/hr) works for V4-Pro if you cap --max-model-len at 800K. Full 1M context on V4-Pro requires a two-node H200 Cluster (~$69/hr).
Here are some templates you can use to get started:
The V4 preview is not a frontier-shifting release in the way R1 was; it doesn't beat GPT-5.5, doesn't beat Opus 4.7, and trails Gemini 3.1 Pro on world knowledge. But that misses the point. V4 is the model that drops the floor of what frontier-adjacent intelligence costs by roughly an order of magnitude, ships open weights under MIT, and slots cleanly into the Claude Code and OpenCode harnesses developers are already using. The practical result is a small handful of workflows like repo-scale code review with prompt caching, long-context document pipelines, formal-math reasoning, and Claude Code redirected at $0.28/M output that simply weren't economical at frontier-lab pricing and are now obvious choices.
For Runpod users, the deployment story is unusually clean for a Day-1 release: Day-0 vLLM and SGLang recipes, LMSYS Org native FP4 MoE on Blackwell, and a sweet-spot configuration (2x H200 for Flash) that runs about $7/hr. The tradeoff to be honest about: V4 is a preview, the long-context retrieval ceiling at 1M is 66% not 99%, and "interleaved thinking across tool calls" is new enough that subtle behavior changes between now and the final release are likely. Treat it as a serious production candidate for the use cases above and a close-to-frontier evaluation target for everything else, and let your next inference invoice settle the rest of the argument.
Author profile: Brendan McKeag
Blog Posts
Iterative AI teams are shifting from hyperscalers to purpose-built AI clouds. Learn how to optimize iteration speed, scale instantly, and cut costs by up to 90%.

Every rented model comes with someone else's roadmap. Runpod's CEO on why the smartest teams are starting to build their own.
.jpeg)
A hands-on tutorial for wiring GPU-backed tools into an MCP server, and hosting the compute on Runpod Serverless.
