.jpeg)
Deploy When Available is now GA
Queue for any GPU spec, even one that's fully rented out, and we'll deploy it the moment capacity opens up. No more refreshing the console or running a sniping tool.
All
Blog
Runpod's new FlashBoot technology slashes cold-start times for serverless GPU endpoints, delivering speeds as low as 500ms. Available now at no extra.


Runpod's serverless journey started just a few months ago, yet we've come a long way. In pursuit of reducing costs, striving for efficiency, and performance improvements, we are finally making FlashBoot available for all endpoints at no additional cost! 🎉
What is FlashBoot?
We have been tinkering this past month trying to reduce cold-starts for GPU-intensive tasks like inference. FlashBoot is our optimization layer to manage deployment, tear-down, and scale-up activities in real-time. The more popular an endpoint is, the more likely FlashBoot will help reduce cold-start. We have seen cold-starts as low as 500ms. 😳
How realistic is this??
Let's get dirty with numbers
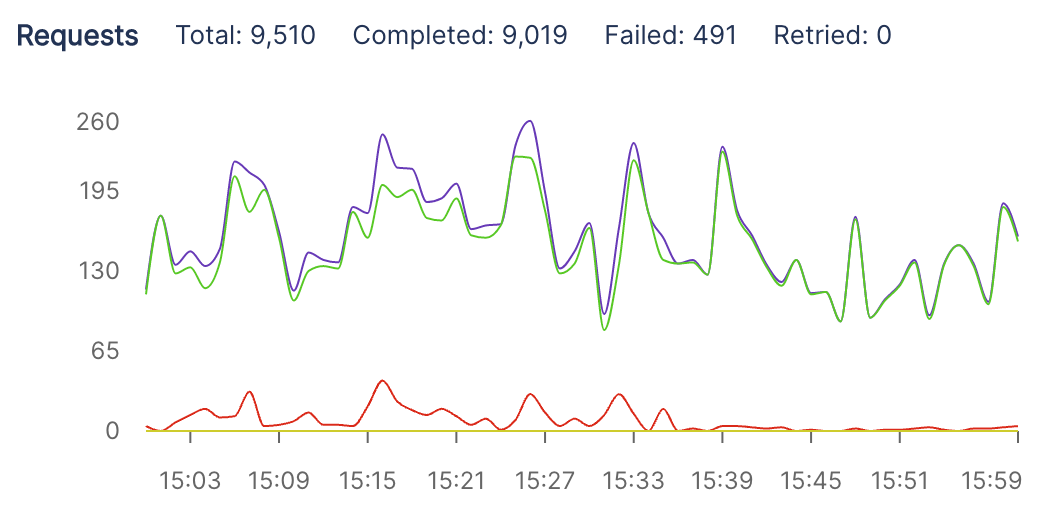
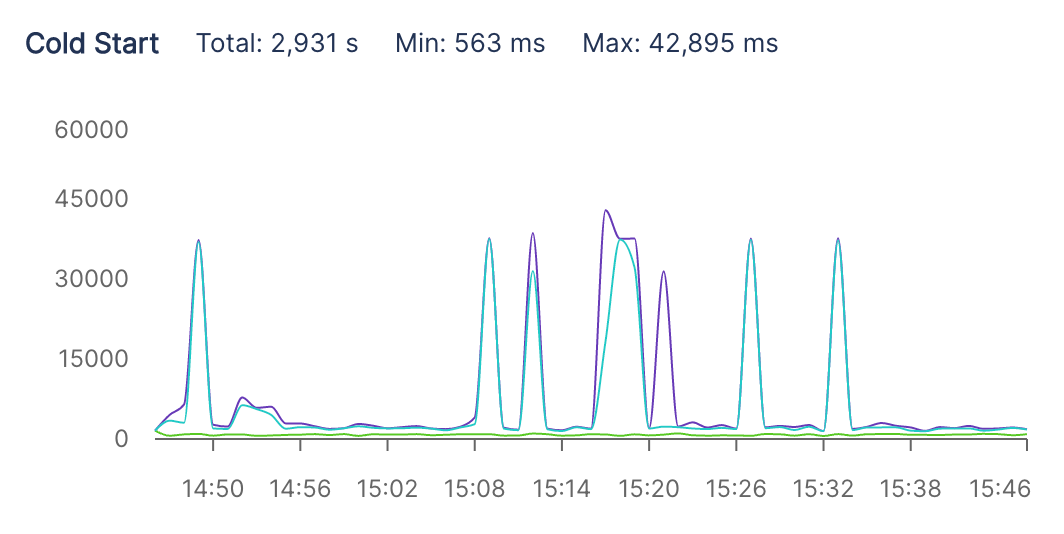
From the above graph, our lowest cold-start was 563 milliseconds, and max was 42 seconds. Without FlashBoot, we would incur 42 second cold-starts, since we load all Whisper models into GPU VRAM (and this takes a long time).
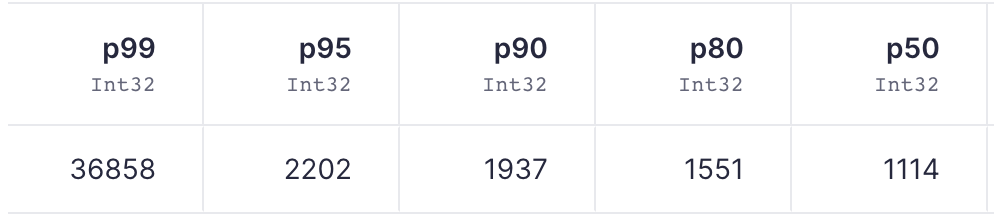
We get a better picture with P99 and P95 metrics. 95% of our cold-starts are less than 2.3 seconds, and 90% are less than 2s! 😍
FlashBoot has helped reduce our cold-start costs for Whisper endpoint by more than 70% while providing faster response times to our users.
Will FlashBoot work for LLMs?
Yes. Flashboot should work for any type of workload. Results may vary, but as long as you have good volume of requests, FlashBoot works! We will be testing LLM functionality in conjunction with Runpod Serverless + FlashBoot in the coming weeks, so stay tuned!
How can I enable FlashBoot?
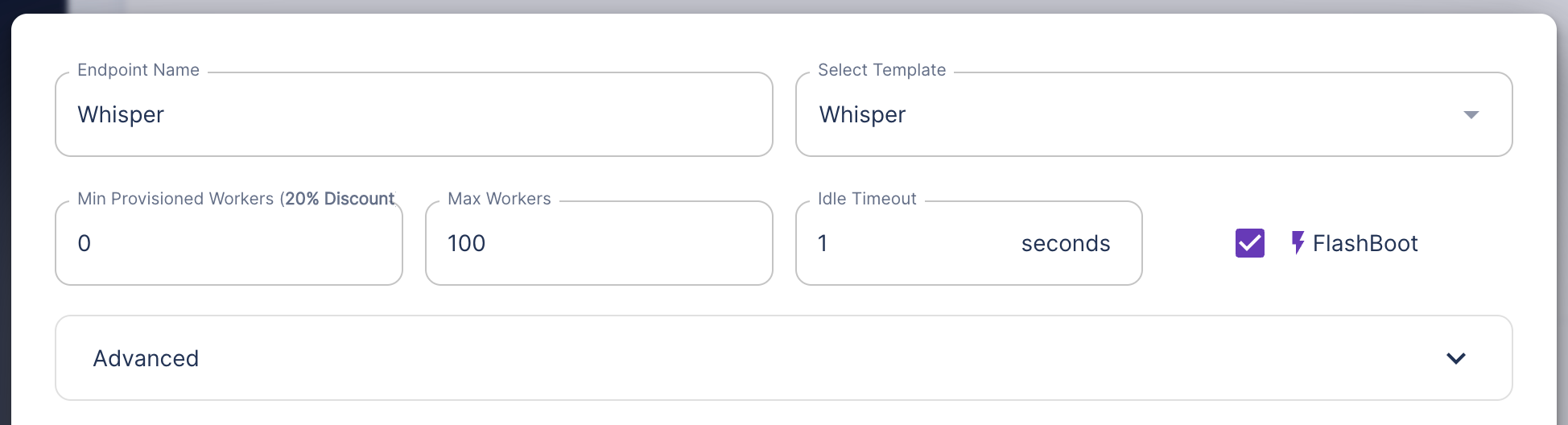
When you create or edit your endpoint, you can enable FlashBoot on the right. While testing, make sure to run several requests to see good results.
We have even more features planned for serverless; until then, enjoy FlashBoot! 😁
Author profile: Pardeep Singh
Blog Posts
Queue for any GPU spec, even one that's fully rented out, and we'll deploy it the moment capacity opens up. No more refreshing the console or running a sniping tool.

Explore why faster chips have shifted the bottleneck to AI infrastructure, and what that means for teams running production workloads.
.jpeg)
With MIG, we can partition RTX 6000 Pro cards into isolated 24 GB instances. Here's when it makes sense for your workloads.
