
Agentic AI Workflows Explained: Patterns, Infrastructure, and GPU Requirements
Agentic workflows plan, loop, and burst differently than a single model call — here's what that means for the infrastructure underneath.
All
Blog
VACE introduces a powerful all-in-one framework for AI video generation and editing, combining text-to-video, reference-based creation, and precise.


As we've written about recently, the video AI landscape just got a massive upgrade. VACE (Video All-in-One Creation and Editing) has arrived as the first open-source model that combines text-to-video generation, reference-based video creation, and comprehensive video editing in a single unified framework. For creators tired of juggling multiple specialized tools, this could be the breakthrough you've been waiting for.
But before you dive in, there's a lot to unpack. Our comprehensive technical analysis reveals both game-changing capabilities and critical limitations that will determine whether VACE fits your workflow.
Traditional AI video workflows are honestly a nightmare. You're constantly switching between AnimateDiff for text-to-video, Stable Video Diffusion for image-to-video, and separate models for editing, masking, and effects. It's like trying to cook a meal while running between three different kitchens.
VACE changes this completely with its groundbreaking Video Condition Unit (VCU) architecture that processes text, images, video, and masks simultaneously through a single elegant interface. Think of it as the Swiss Army knife of video AI, except this one actually works as advertised.
The model's "Anything" suite sounds almost too good to be true. Move-Anything lets you reposition objects within video scenes, Swap-Anything replaces characters or objects seamlessly, Reference-Anything generates videos based on reference images, Expand-Anything extends video sequences naturally, and Animate-Anything brings static elements to life. Unlike the marketing promises we've all grown tired of, VACE actually delivers on these capabilities, though with some important caveats we'll dive into. Much of what VACE can do is powered by the video input function in the workflow that allows you to extract depth information from a video, essentially anonymizing the subject, and then "projecting" your own reference image onto it.
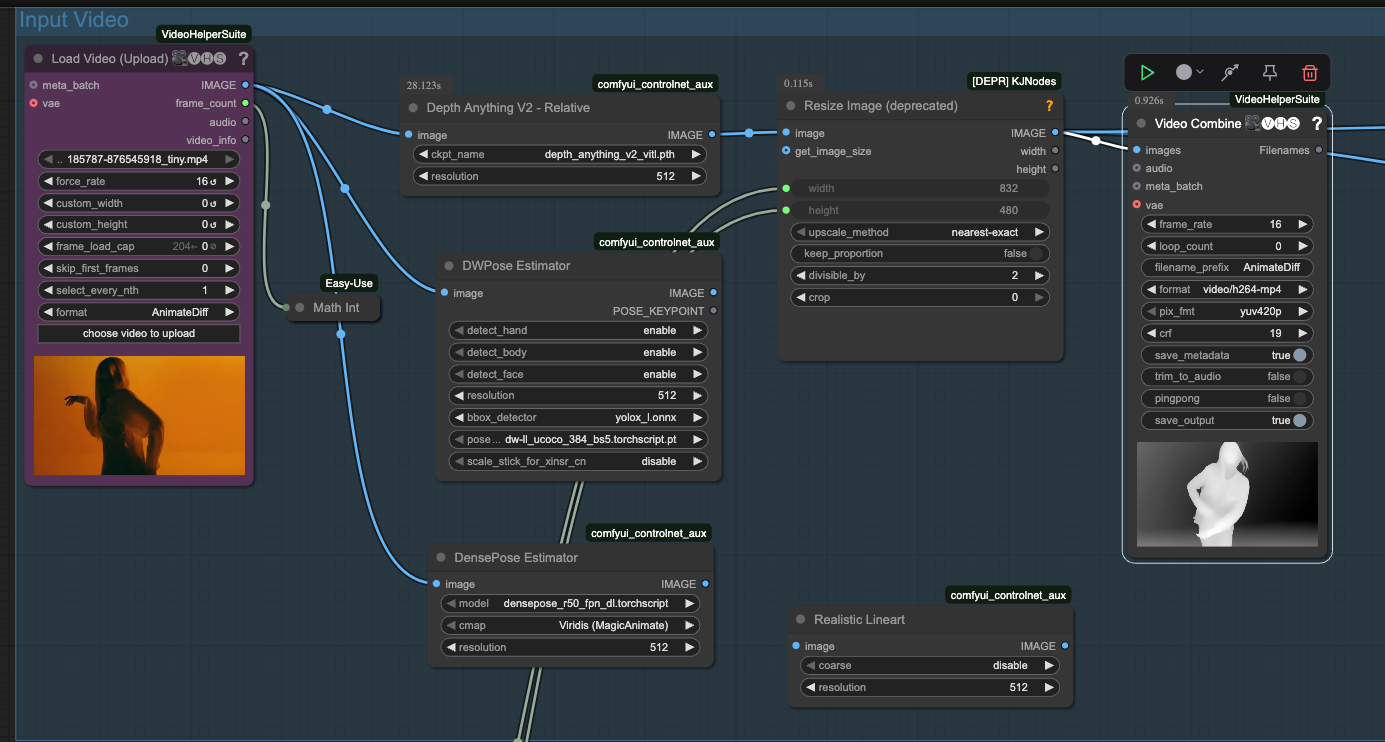
VACE comes in two distinct flavors, each with its own personality. The 1.3B parameter model requires 8.19GB of VRAM officially, though real-world usage often laughs at this number and demands more. It's optimized for 832×480 resolution and can pump out 5-second 480P videos in about 4 minutes on RTX 4090 hardware. This version works well for consumer setups, prototyping, and educational applications.
The 14B parameter model is a different beast entirely. While it officially supports up to 720P resolution, it frequently requires 48GB or more VRAM for stable operation. The performance is significantly slower but delivers superior quality when it works properly. This version demands production environments with multi-GPU setups and isn't for the faint of heart or shallow of wallet.
The unified approach delivers several distinct advantages that make it worth considering despite its quirks. Unlike Stable Video Diffusion's basic image-to-video conversion, VACE offers integrated pose control, depth control, and ControlNet integration. You get precise control over every aspect of your video generation rather than crossing your fingers and hoping for the best.
Resolution-wise, VACE handles up to 720P with the larger model, which is a significant step up from AnimateDiff's typical 512×512 limitation. This resolution boost makes a real difference for professional applications where quality matters.
The licensing situation is refreshingly straightforward. VACE operates under Apache 2.0 licensing, giving you complete commercial freedom compared to more restrictive alternatives. No lawyers needed, no licensing fees to worry about, just pure creative freedom.
From an infrastructure perspective, running one unified model instead of multiple specialized tools dramatically reduces server costs and maintenance overhead. This advantage becomes particularly compelling for production deployments where every dollar and hour of maintenance time counts.
Here's where things get interesting, and by interesting, I mean potentially frustrating. The 14B model is an absolute resource monster. Even with 48GB VRAM configurations, users frequently encounter out-of-memory errors that'll make you question your life choices. Real-world VRAM usage consistently exceeds quoted specifications, especially for extended sequences.
The resolution versus stability trade-off presents a harsh reality check. The 1.3B model advertises 720P capability but produces "generally less stable" outputs at this resolution. The documentation itself explicitly recommends 480P for "optimal and more stable results." If you need consistent 720P output, you're looking at 14B model deployment with all the multi-GPU requirements that entails. Moving from 480×832 to 720×1280 doesn't just increase your processing time by the resolution ratio — it explodes exponentially. That same 4-minute generation at 480×832 with 30 steps becomes approximately 16 minutes at 720×1280. Jump to 1080×1920 and you're looking at roughly 64 minutes for the same content. The VRAM requirements follow a similar exponential pattern, turning a manageable 12GB requirement into 24GB, then 48GB+ as you climb resolution ladders.
This means a seemingly modest resolution bump from 832×480 to 1280×720 can quadruple your processing time and double your VRAM requirements. When you're paying for GPU time by the minute, these exponential increases add up fast. A project that costs $5 to render at lower resolution suddenly becomes a $20+ expense at higher resolution, and that's assuming you don't hit memory limitations that force you into even more expensive multi-GPU configurations. Because VACE is an additional model on top of all of this, it can add even further overhead on top of what could already be a very expensive process.
VACE's character consistency capabilities work beautifully under controlled conditions. Simple to moderate poses, controlled diffused lighting, stable clothing without complex textures, and short sequences within that 81-frame sweet spot all play nicely together. High-resolution reference images at 576×1024 or 1280×720 with clear facial features and consistent lighting produce reliably good results.
Additionally, bear in mind that making large scale changes based on a reference image can be problematic if not impossible. How much that the model will adhere to your original reference is controlled through the "strength" variable. A high strength means high adherence to the source material, lower strength gives the model more leeway. If you have, say, a reference image of a woman in a red dress, and you want to put her in a blue dress, that's going to be an issue. Because this is a large shift of pixels, a high strength value means that you can keep the likeness of the woman, but it will be unable to appreciably change the color of her dress because it adheres to all aspects of the source. A low strength will allow for large changes in clothing, but then it will also allow the process to change the likeness of the reference. Something like this would require a LoRA to be trained to attain the results you're looking for.
Despite all the built-in reference capabilities, LoRA training remains necessary for unique or stylized character designs, high-fidelity requirements across varied conditions, and complex costumes. The optimal approach combines both methods: use VACE's reference features for initial generation and rapid iteration, then apply character-specific LoRAs for problematic scenarios requiring precise control. So, like any good workflow, it starts with defining the requirements: visualizing what you're looking to get out as the final result, and then determining what you need to spend to get there.
One significant limitation that affects creators looking to generate longer video sequences involves RIFLEx, a breakthrough technique for length extrapolation in video diffusion models. RIFLEx allows models to generate videos significantly longer than their original training sequences through clever modifications to the rotational position embedding (RoPE) mechanism. Unlike the limitations of VACE, it essentially is a "free lunch" solution that can extend video generation capabilities without requiring expensive retraining.
The technique has proven remarkably effective with video diffusion models, enabling 2x and higher temporal extrapolation that can turn short clips into much longer sequences. RIFLEx works by identifying and modifying intrinsic frequencies in the model's positional encoding, allowing it to maintain coherence across extended timeframes that would normally cause quality degradation or repetitive patterns.
Unfortunately, VACE's fundamentally different unified architecture means that RIFLEx's modifications to the RoPE mechanism simply don't translate over. Essentially, RIFLEx applies to the Wan model, but not the VACE model. The technique relies on specific positioning and frequency calculations that are tailored to how these other models handle temporal information, and VACE's approach to unifying multiple video tasks creates incompatibilities at the architectural level, so as long as you have VACE piggybacking on top of Wan, you'll be limited to the base 81 frames that Wan offers.
VACE represents a genuine step forward in unified video AI, but it's not a magic bullet that solves every workflow challenge. Like any powerful tool, success depends on understanding both its capabilities and constraints. Start small, test within the optimal parameters, and gradually expand your usage as you learn the system's quirks. For many creators, the unified workflow benefits will outweigh the technical limitations, especially as the technology continues to mature. The question isn't whether VACE is perfect –— it's whether the trade-offs align with your specific needs and budget. In a rapidly evolving field where tool fragmentation has been the norm, VACE's unified approach feels like a glimpse of where the entire industry is heading.
Author profile: Brendan McKeag
Blog Posts
Agentic workflows plan, loop, and burst differently than a single model call — here's what that means for the infrastructure underneath.

What eleven teams built at the Runpod Flash Hack Day, and the three demos that took home the top prizes.

We tested four models across sixteen workload profiles. Here's exactly what we measured and how.
