In 2023 and 2024, the infrastructure conversation was almost entirely about training: how to run distributed jobs across A100s, how to saturate NVLink, how to handle gradient synchronization at scale (RoCE networks for distributed AI training at scale, Engineering at Meta). That conversation is still relevant, but it's no longer the primary constraint for most production teams (CES 2026: AI compute sees a shift from training to inference).
In 2026, the daily fight is inference: latency-per-token, throughput under concurrent load, and cost-per-request at the tail of your traffic distribution. Your model is already fine-tuned. Now it needs to serve 10,000 requests per hour with p99 latency under 500ms, and your infrastructure bill needs to scale with revenue rather than ahead of it. If you're a CTO or technical founder scaling an AI product, not building frontier models at trillion-parameter scale, this is the infrastructure playbook that applies to you. Teams that are getting this right tend not to be the ones who built the most sophisticated custom stack; they're the ones who figured out what not to build.
The 2026 AI Infrastructure Stack: What Actually Changed
The four foundational layers, compute, networking, storage, and orchestration, haven't changed. What's changed is what each one looks like in practice, and what teams increasingly choose to own versus delegate.
Compute has split cleanly into three access models: reserved capacity for predictable, high-utilization workloads; on-demand pods for burst and experimentation; and serverless for request-driven workloads that scale to zero between traffic spikes. Choosing the right billing model can save 40 to 80% on GPU spend. Teams that treat all three as interchangeable pay the wrong price at every tier.
Networking has matured faster than most teams' assumptions. Ethernet is now outpacing InfiniBand for AI back-end fabrics, which makes high-bandwidth Ethernet a practical option for multi-node training. The deployed standard for high-end fabrics today sits around 800 Gbps; 1.6 Tbps switching is only beginning to ship in volume in the second half of 2026, with 3.2 Tbps on the roadmap toward the end of the decade. The Ultra Ethernet Consortium's 1.0 specification is the reason that gap is closing.
Storage is shifting toward network-persistent volumes as the recommended default for multi-node training, used alongside local NVMe rather than as a wholesale replacement. Checkpoint survival across node failures is a well-architected managed-storage pattern, not something you should be engineering yourself.
Orchestration is where the biggest shift has happened. Control planes that handle HPC cluster setup, inter-node addressing, and job scheduling topology have replaced the assumption that every team needs to own and operate raw infrastructure. Google Cloud has productized the HPC control plane as Cluster Director, a clear signal that the orchestration layer is becoming managed product rather than DIY engineering. The stack has unbundled. You no longer need to own every layer to run production AI.
Each layer below ladders up to one decision, build or buy; the flowchart that synthesizes them is at the end of the article.
Compute: GPU Tiers, Access Models, and the Real Cost Equation
H100 and A100 remain the practical 2026 production choices for fine-tuning and inference. Blackwell (B200 architecture) matters for trillion-parameter pre-training; if you're operating at that scale, you already know why. For the rest of the distribution, the H100 is the right answer for high-throughput inference and large-model fine-tuning, and the A100 remains cost-effective for workloads where memory bandwidth isn't the primary bottleneck.
The access model is where most teams get the cost equation wrong. Across Runpod's 500,000-plus developers, one of the two most common infrastructure failure modes is GPU utilization clustering below 50% on on-demand workloads, until teams move to a workload-matched access model.
Reserved capacity (sold on Runpod as Savings Plans) locks in price predictability and guaranteed access. The breakeven makes sense when you're running continuous workloads at high utilization: production inference behind a latency SLA, or regular fine-tuning runs on a defined schedule. You're trading flexibility for cost efficiency, and that trade is worth making when your utilization data supports it.
On-demand pods (billed per minute with no minimum commitment) are correct for experimentation, one-off fine-tuning runs, and burst capacity. The per-hour cost is higher than reserved, but the flexibility more than compensates if your utilization would otherwise sit below 60 to 70%.
Serverless compute bills per second of worker active time, with no idle GPU spend once workers have fully scaled to zero between bursts. For workloads with variable or unpredictable traffic, which describes most production inference at the early-to-growth stage, serverless is the right cost model.
Most teams track dollars per hour. That's the wrong number. For inference, track cost per output token, which NVIDIA argues is the only metric that matters for inference economics. For training, track utilization percentage as a primary signal, and consider Model FLOPs Utilization (MFU) for a more precise view of compute efficiency.
The math is unforgiving: an H100 at 30% utilization costs roughly 3x more per useful compute unit than the same GPU running at 90%. A team running a 10-dollar-per-hour H100 at 30% utilization is effectively paying 33 dollars per hour for the compute it actually uses. That gap funds more than reserved capacity; it funds product development.
Once the compute access model is right, the next optimization layer is how you serve requests on that compute, which is where inference infrastructure decisions determine your actual cost per token.
Inference at Scale: The Layer That Runs Your Product
Training runs once per model version. Inference runs on every user request. The infrastructure requirements are inverted, and teams that build inference infrastructure like it's a training problem end up with the wrong tradeoffs everywhere.
For training, you optimize for raw FLOP throughput and checkpoint reliability. For inference, you optimize for cold start latency, concurrent request throughput, and per-request cost. None of those share an optimization target.
The standard framework stack for production inference in 2026:
vLLM handles continuous batching to deliver up to 23x throughput over naive serving under concurrent load. PagedAttention's virtual-memory KV cache eliminates the fragmentation that makes naive serving inefficient at high concurrency. For serving open-weight models like Llama 3.1 70B Instruct, Mistral 7B Instruct v0.3, or Mixtral 8x7B Instruct v0.1 at production throughput, vLLM is the starting point, not because it's the only option, but because it handles the common case well and has the broadest model compatibility.
SGLang is the right choice when your inference pattern isn't a single prompt-response exchange but a structured multi-step workflow: agents that chain LLM calls, pipelines where output format needs to be constrained, or multi-turn systems where KV cache reuse across requests matters. SGLang's RadixAttention enables automatic prefix sharing across requests, which cuts compute cost significantly in agent-style workloads. If you're building anything that chains multiple LLM calls per user request, benchmark SGLang against vLLM for your specific access pattern.
Ray handles the case where a single GPU's VRAM can't hold your model. A 70B model at fp16 needs roughly 140GB of VRAM, more than the 80GB on an H100. At INT8 quantization the footprint drops to about 70GB, borderline on an H100 SXM and comfortable on an H200's 141GB of HBM3e. For models that genuinely exceed even an H200 at any practical quantization, Ray Serve with tensor parallelism spreads the model across multiple GPUs without custom distributed inference code. The networking and cluster topology that make multi-GPU Ray deployments practical are covered in the networking section below.
Framework choice is the software-stack decision. Whether that stack actually performs in production comes down to three operational concerns: how fast workers come online (cold start), how you pay for them when traffic is bursty (serverless billing), and how you watch them under load (observability).
Cold start latency is the number that will ruin your p99 SLA if you're not actively managing it. Multi-second cold starts on GPU workers destroy latency budgets for request-driven workloads. Runpod's cold-start optimization for serverless endpoints reduces infrastructure-level cold starts to as low as 500ms (P90 under 2.0s, P95 under 2.3s) by retaining worker state after scale-down rather than fully tearing down and reinitializing the container. These figures reflect infrastructure startup overhead only, for large models, total time until the first token is served also includes weight loading into GPU memory, which adds several seconds for 7B models and can reach 30+ seconds for 70B+ models. For model weights specifically, the Advanced settings on each endpoint include a model caching toggle that eliminates repeated weight-load times across scale-up events. Enable the caching toggle by default for endpoints serving large models; the benefit scales with model size.
Serverless endpoints bill on actual compute time used, not reserved capacity. Workers scale to zero when idle, which stops the billing clock. Variable traffic patterns, which describe most AI product traffic before you've hit scale, don't need a reserved GPU sitting idle between request bursts.
Observability for production inference starts with the built-in Prometheus metrics endpoint in vLLM: pass --enable-metrics to vllm serve, then scrape :8000/metrics. Track vllm:e2e_request_latency_seconds, vllm:num_requests_running, and vllm:gpu_cache_usage_perc. These three tell you when to scale workers and when your batching configuration is suboptimal, before your users notice.
Single-endpoint optimization covers the common case. When your model exceeds single-GPU VRAM or your training pipeline spans multiple nodes, the constraints shift to the network fabric and storage layer, the other half of the production failure surface.
Networking and Storage: The Layers That Break Distributed Training
A common failure mode during distributed training bringup is misconfigured inter-node networking, and it's the layer most likely to break your distributed jobs in ways that are hard to diagnose. Gradient synchronization during AllReduce operations is synchronous: if one node's network link is congested or asymmetric, every other node in the job waits. A poorly provisioned network doesn't produce clear errors; it produces training jobs running well below expected throughput, sometimes at 40 to 50% of peak, with no obvious cause.
Runpod's Clusters provision nodes in the same data center with 1600 to 3200 Gbps inter-node bandwidth. Dedicated high-speed interfaces (ens1 through ens8) handle framework communication, PyTorch's NCCL backend and Slurm's MPI layer, while the primary node's eth0 handles external traffic. One reproducibility detail matters here: set NCCL_SOCKET_IFNAME=ens1 in your distributed training environment so NCCL binds to the high-bandwidth fabric rather than defaulting to eth0. Network isolation between clusters means bandwidth contention from other tenants doesn't affect your gradient sync throughput. Standard shared-networking cloud setups provide far less dedicated bandwidth per node, which is why multi-node jobs that run fine at 2 nodes often fall apart at 8 or 16.
Networking is one silent-failure layer in distributed training. Storage is the other: misconfiguration here doesn't surface until the run is already lost. The right tier comes down to one question, how long your data needs to outlive the compute:

As a practical default, attach a network volume when running distributed training on Clusters. Network volumes mount at /workspace on every node in the cluster, persist independently of compute lifecycle, and are retained when the cluster is terminated. Volume disk persists across Pod stops and restarts within /workspace but is deleted on termination. Container disk is ephemeral; it's gone when the worker stops.
Losing a training run to storage misconfiguration at hour 18 of a 24-hour job is a painful way to learn which tier survives what. Default to network volume for anything you can't afford to recompute.
Orchestration: Why the Kubernetes Path Costs You Two Weeks
Here's the actual bill of materials for self-managed AI infrastructure in 2026: a bare metal GPU provider, a service contract, a cluster management layer (Kubernetes plus Helm), an HPC job scheduler (Slurm or Anyscale), a training engine, an inference engine, and an engineer who understands how all of it fits together and is available when something breaks.
That's not a one-time setup cost. It compounds. Every new team member needs to understand the full stack. Every hardware change requires reconfiguration of the Kubernetes GPU operator stack. CUDA version mismatches between container images and the host driver surface at the worst possible times, usually against a deadline. Driver updates that break a working cluster are a recurring cost, not a one-time concern.
The hidden line item is engineering time. Two engineers spending a week standing up this infrastructure at a combined salary of 150,000 dollars per year, a conservative figure given current AI/ML market rates, is roughly 3,000 dollars in opportunity cost before you've run a single training job. Do it twice a year and you've spent 6,000 dollars on plumbing that adds zero model quality, zero inference throughput, and zero product value.
Runpod removes this setup chain using Slurm Clusters. Clusters deploy with one node automatically designated as the Slurm Controller and the remaining nodes as Slurm Agents; the HPC job scheduling topology is pre-configured, not manually assembled. For PyTorch distributed training, the platform pre-populates environment variables and node addressing across the cluster: MASTER_ADDR, MASTER_PORT, WORLD_SIZE, and RANK are set automatically. Launch your training script with torchrun, or with srun inside a Slurm job, and dist.init_process_group(backend='nccl') works without manual host file configuration. You will still set NCCL_SOCKET_IFNAME=ens1 so NCCL binds to the high-bandwidth fabric, as covered in the networking section. The Clusters quickstart provides a working distributed training template that you clone and adapt rather than build from scratch.
For teams that need to go deeper, custom Slurm configuration, specific scheduling policies, or priority queues, the controller node is accessible and /etc/slurm/slurm.conf is modifiable. The pre-configured state is a starting point, not a ceiling.
Runpod's platform is software-orchestrated: its Private Cloud offering lets it connect to external and customer-owned compute rather than being constrained to provider-owned hardware. Customer-owned hardware and private pools can be managed through Runpod's orchestration layer alongside cloud instances. The platform is designed to support that progression without replatforming, though you should verify the specific API surface for your target configuration against Runpod's documentation.
Build vs. Buy in 2026: A Practical Decision Framework
Every layer you've just worked through (the GPU cost equation, the framework and operational choice, the silent-failure surface, the orchestration overhead) ladders up to one decision: build or buy. There are three honest paths through that decision, with the specific thresholds mapped in the flowchart below.
That decision has a clearer answer in 2026 than it did in 2023. The managed layer has matured. Teams have also paid the real cost of self-managed infrastructure often enough to have reliable data on what it actually takes, not the optimistic estimate at the start of a project, but the actual cost after six months of maintenance.
Here's a framework for making the decision:
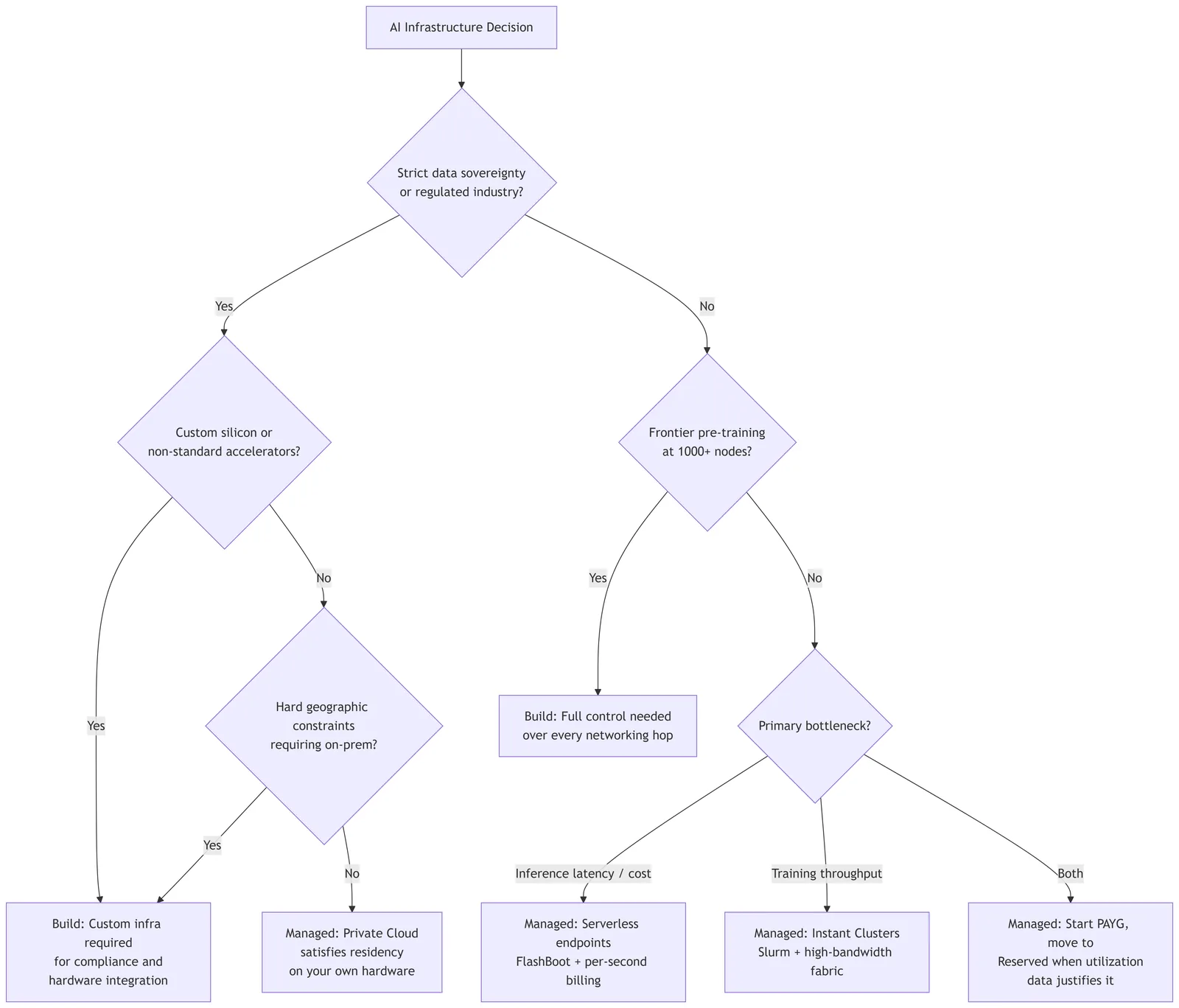
When building is justified: Strict data sovereignty in regulated industries, healthcare data under HIPAA, or financial data with geographic residency mandates can justify custom infrastructure. Custom silicon integration for non-standard accelerators or custom ASICs does too. Frontier model pre-training at thousands of nodes where you need full control over every networking hop is legitimately a case for owning the stack.
That said, even the data sovereignty argument has narrowed. Runpod's Private Cloud offering lets you run the same orchestration layer on your own hardware, satisfying residency requirements without rebuilding your deployment tooling.
When managed wins: Standard inference serving on open-weight models. Burst capacity for spiky request loads. Early-stage iteration before your workload patterns are stable enough to justify reserved capacity commitments. The per-second billing model with no egress fees on common workflows means infrastructure cost scales with revenue rather than ahead of it. That's a structurally different risk profile than committing to reserved capacity before you know your utilization patterns. As the compute section established, variable traffic is the default at the early-to-growth stage, which is why serverless billing is the right starting model for most teams.
The hybrid progression: Start on pay-as-you-go (PAYG), validate your workload patterns, then move to reserved capacity when utilization data justifies it. From there, move to private hardware through Runpod's Private Cloud offering if your economics or compliance requirements demand it. Core APIs are consistent within tiers; confirm the full API surface for a Private Cloud deployment against Runpod's current documentation before committing.
The engineering-time argument works in both directions. If your team has genuine infrastructure expertise and the problem is truly differentiated, you're doing something at a scale or with a hardware configuration that no managed platform can support, building is justified by genuine differentiation. If you're a product team that happens to need GPU infrastructure, you're paying engineers to maintain undifferentiated plumbing. That's an exchange of scarce engineering time for commodity infrastructure that most early-stage teams shouldn't make.
Getting Started: Serverless Endpoint or Cluster in Under 10 Minutes
Pick the path that matches your current bottleneck.
Path A: Serverless inference endpoint
If your bottleneck is inference latency or per-request cost, start with Runpod Serverless.
Before you start, you'll need a Runpod account with a payment method on file (GPU access requires a funded wallet even on the first deploy) and an API key from Settings, then API Keys. You'll use the API key to authenticate runpodctl in a moment.
Navigate to the Serverless section in the Runpod console and select New Endpoint to deploy a worker. Choose your deployment source, Git Repository, Docker Registry, or a Ready-to-Deploy repo if you're starting with a standard vLLM or SGLang configuration. Configure GPU type, worker type (Flex workers scale to zero between requests, best for bursty traffic; Active workers stay on continuously at a ~21% discount, cost-effective once monthly utilization exceeds ~25%), and max workers (autoscaling ceiling); the endpoint settings reference documents every option. Enable the cold-start optimization in the performance settings. Deploy.
For CLI-based management, install runpodctl first:
Authenticate:
Verify the install:
For the latest flag reference, check the runpodctl release notes before scripting deployments; the CLI is actively developed and command signatures change between minor versions.
Path B: Distributed training cluster
If your bottleneck is training throughput, or you're scaling a fine-tuning pipeline to multiple nodes, start with Clusters.
Open Clusters in the console, select Create Cluster, then choose Slurm Cluster from the cluster type dropdown. Set pod count, GPU type (H100 for large-model fine-tuning, A100 for most other workloads), and pod template. Before deploying, attach a Network Volume; it mounts at /workspace on every node and persists across the entire cluster lifecycle.
Connect to the Slurm Controller node via Jupyter or terminal. The platform has already populated the PyTorch distributed environment variables across all nodes (MASTER_ADDR, MASTER_PORT, WORLD_SIZE, and RANK, as described in the orchestration section above). Set NCCL_SOCKET_IFNAME=ens1, launch with torchrun or srun, and dist.init_process_group(backend='nccl') works without additional host configuration. Follow the Runpod Clusters quickstart to adapt the provided distributed training template to your workload.
For Ray-based workloads, Ray is a supported framework on the same Cluster topology; consult the Runpod documentation for the specific Ray job submission workflow.
Conclusion: Making the Right Infrastructure Call in 2026
The AI stack has matured faster than most teams' infrastructure practices have. In a 2026 production environment, the teams that win spend their engineering cycles on model quality and product development rather than on cluster maintenance and networking configuration.
Build-vs-buy is clearer now than it was two years ago. Managed orchestration handles the common cases well. Self-managed infrastructure is still justified for genuinely differentiated requirements, but those cases are narrower than most teams assume when they first stand up a cluster, given how much of the common case today's managed orchestration platforms already cover.
The team that opened this article with a p99 SLA problem and an unpredictable inference bill has a clear path: serverless endpoints for variable traffic, reserved capacity once sustained utilization climbs past the 60-to-70% band, and Clusters when multi-node training throughput is the constraint. None of those require weeks of upfront cluster engineering.
Stop spending two weeks on cluster setup. Deploy your first GPU workload in minutes. Get started at runpod.io.


